
游戏的角色语音管理是一项细致且繁琐的工作。从项目的前期到后期,会遇到对角色语音的增删改查、添加动态效果处理及创建不同语种间的切换等需求。建立一套稳定可靠的语音管理流程会为工作带来效率。
采用Wwise External Source
不采用Wwise时的工作方式
不采用音频中间件的项目一般采用数据库作为和故事编辑器(StoryEditor)沟通的桥梁。所有的语音文件通过数据库来进行管理,便于执行增删改查及其他拓展配置。
 图 1管理表格举例(这里选的SFX资源,Voice资源也是同理)
图 1管理表格举例(这里选的SFX资源,Voice资源也是同理)
比如,上图的表格大家都不会陌生——我们在Excel里安排了ID、声音类型、文件名、文件路径、以及输出Bus(Output)等等的列标签。在项目运行时,据此调用文件的ID或者文件名,找到各个文件的真实路径,进行一系列的约定处理(设置)——比如这里的Output就是对应不同声音类型的输出Bus,最终音频文件得以正确播放。
采用Wwise时的工作方式
同样的思路也可通过Wwise提供的 External Source来完成。我们可以把External Source理解成一个具有通用属性(Actor-Mixer Property)的模板,在项目运行中程序将指定的原始语音资源放入这个模板,模板上的属性由我们在Wwise里提前设置,或者项目运行时代码实时设置,最后播放出带有特定属性的声音。
我很喜欢这条思路,它既能利用到数据库的便捷性,又可利用到Wwise引擎的强大功能,因为角色语音文件是大批量的单句资源,同时具有通用属性的资源量也多,不像SFX需要配置很多播放逻辑(各种switch、blend、sequence、delay巴拉巴拉),所以很适合采用External Source来实现。
External Source作为“模板”
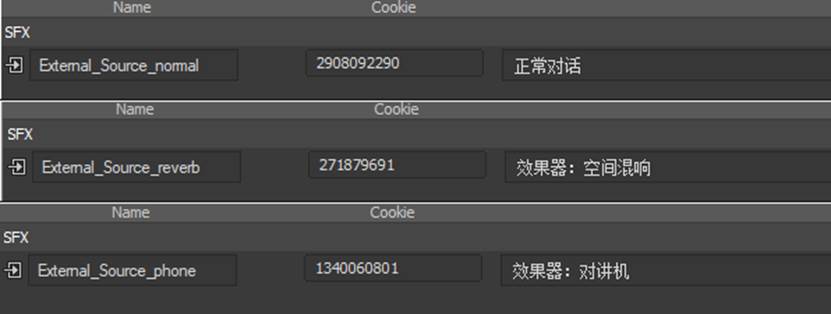 图 2多个不同用途的external_source
图 2多个不同用途的external_source
External_Source可以被创建多个,并分别用作对应不同声音类别的“配置模板”。如上图,我们创建了三个External_Source,(一定记得各自重命名(Name),这样才会自动生成各自的哈希索引(Cookie))其中External_Source_normal为通用对话使用的模板,External_Source_reverb为使用了混响辅助发送的模板,External_Source_phone则为用于为语音增加对讲机效果的的模板(例如,插入了EQ及失真效果器)。
当然,这只是个简单的示例,在实际项目中需要根据具体情况,结合声音对象属性(Effects、Positioning、Output Bus、Aux Bus等等)进行更有针对性的设计。
需要注意
通常,灵活也意味着更多的工作。音效师需要根据自己的项目,应需设计不同的External_Source、不同的Output Bus、或静态/动态加载的效果器等等。这也需要和程序员在数据库的设计上进行沟通及做出约定,记得程序的工作量也会相应增多。当然,具体工作量跟项目的大小、复杂度有关。能实现特定需求的设计可能性有很多,尽量找到大家都省事的方案。
使用WAAPI批量导入语音
Wwise的语言管理器(Language Manager)为多语言版本的切换提供了支持——我们可以把语音文件的不同语言版本分别导入”Sound Voice“,设置好语言版本,并定义和管理好对应的语音Event以及Soundbank。
虽然Wwise提供了Auido File Importer、Voice Asset Importer之类的工具,比如可以基于TabDelimited文本文件导入,基于模板(Template)导入,以及采用Localize languages的导入模式等。但是,经过笔者的实验验证,对于批量导入多语种语音来说会显得有点繁琐,容易出错。对于此需求,采用WAAPI进行批量化导入会是一个明智的选择。这里提供一个脚本分享一下思路:
https://github.com/aadsache/waapi_tools/tree/main/voices_importer
- 首先约定外部的资源管理器文件结构为:Voice(folder)//Character_name(folder)//EN_xxx.wav
- 具体的音频文件会有一个前缀代表它的语言版本:EN_xxx.wav/CN_xxx.wav
- 约定要创建Audio项下的层级结构为:Default Work Unit//Voice(Folder)//Character_name(Actor_Mixer)//xxx(Sound_Voice)
- 根据音频文件的前缀EN\CN指定Sound_Voice下的语言版本English(US)\Chinese
- 约定要创建Event项下的层级结构为:Default Work Unit//Voice(Folder)//Character_name(Folder)//xxx(Event) ,并分别定义好Auido项下对应xxx(Sound_Voice)的播放行为
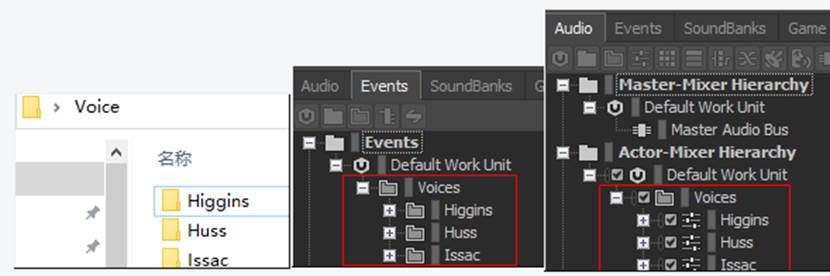 图 3各界面的层级图
图 3各界面的层级图
这里有几个小提示,WAAPI对象的导入和创建可采用merge、useExisting这样的模式,这样就可避免之前就存在的资源、对象不会被重新导入、创建;工作中搭配数据库使用WAAPI依然是必要的。
以上是导入双语言版本语音并设置event的小实验,工作中还应采用更规范化的做法,这里只是提供了一个思路。以下还有几个值得拓展的地方:
#可以配合Add-ons来配合使用WAPPI——Add-ons也可以做出很多有意思的事情,拓展出更多的功能。
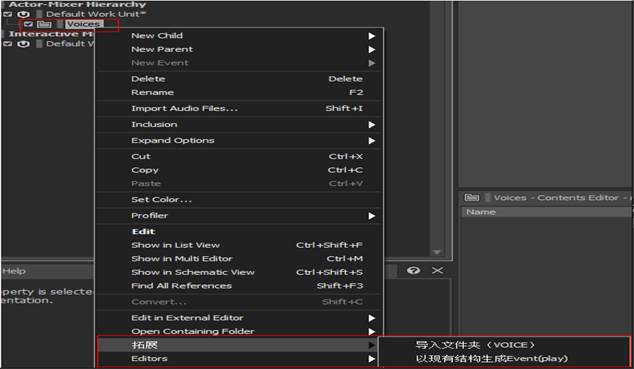 图 4Add_on的拓展思路
图 4Add_on的拓展思路
#配合数据库也可做很多拓展。比如Waapi不仅仅只是能导入音频文件,也可以同时指定对象属性,如音量(Volume),输出(Bus)、发送(AuxBus)等等。对于低延迟要求不高的语音文件,可以同时设置磁盘流式播放模式(Stream)来可以减小内存的占用。("@IsStreamingEnabled" : True,"@IsNonCachable":True)
#值得一提的是如果把注释(Notes)用来放语音文件的台词,那简直太酷了!
具体操作可以参考此脚本(https://github.com/aadsache/waapi_tools/tree/main/importer_withnotes),如图,可以直接在Wwise搜索框通过搜索台词字符内容,找到相关声音对象。但是这里搜索框不能做到高级搜索,必须从第一字符就要严格匹配才能搜索到。
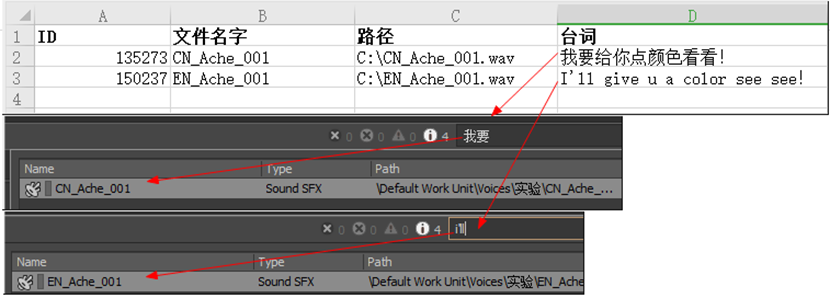 图 5 按台词查找声音对象
图 5 按台词查找声音对象
动态语音及其他
Wwise提供了Dynamic Dialogue来灵活性、选择性地完成对白,也可通过其他(container、switch、RTPC等)工具搭建自己的对话系统,会稍微有点复杂,但是思路上也挺有意思。这里笔者压制了两个中文字幕的视频,分别关于Dynamic Dialogue、Interruptible Dialog的案例演示。
(国内观赏视频通道)
(国内观赏视频通道)
希望能带给大家一些帮助,如有纰漏,欢迎大佬们指正。

评论