
基于对象的声音系统
市场对于沉浸式音频体验的渴求催生了一批远超7.1的扬声器设置,在包括增强式二维性能的同时增加了高度这一维度。这也迫使一些类似Dolby Atmos和DTS:X的环绕声系统以及MPEG-H这类新兴发布格式推出了音频对象的概念,以便将扬声器配置抽象化,而空间化的音频内容也会在这个配置基础上渲染。
基于声道的音频和基于对象的音频有一个非常重要的区别就是基于声道的音频从制作阶段到回放都依靠固定数目的声道,而且音频混音是针对严格的扬声器配置设计或是必须进行下混来适应更简单的扬声器设置。基于对象的音频意味着“音频对象”(即单声源+相对于听者的3D坐标)必须留存,并交给渲染器根据用户设置进行空间化。换句话说,基于对象的音频将“对象”或音频元素视为独立的流,并且允许每个流含有元数据来描述该音频对象应在三维空间的何处播放,这些元数据与扬声器设置无关。音频对象在制作过程中可以独立被精确地放置在空间中,而且每个音频对象都是经过一个叫做自适应渲染的流程针对正确的扬声器组合进行实时渲染,而自适应渲染会考虑扬声器布局。自适应渲染也允许对在接收端的渲染进行调整。
VR音频中常用的双耳虚拟化用对象范式来解释会很好理解。双耳化流程一般都是将每个独立的音频对象通过一个滤波器(HRTF)。它的频率响应取决于声源相对于听者的3D位置。
留存对象的缺点
虽然基于对象的音频希望从空间的角度优化渲染质量,但是留存对象在音频设计流程上本身就有限制,因为它与一些重要的音频创作手法不兼容。
比如,声音设计师想要控制一组声音的动态范围。他们一般的做法是在汇集所有输入声音的总线上添加压缩器-换句话说,就是创建一个子混音。子混音的采用也有别的各种原因,例如:
- 性能
- 旁链
- 母带处理
- 电平计量,响度计量
- 分组
在Wwise里,Master-Mixer Hierarchy(主混音器层级)的对象就用于这些目的。总线在需要的时候可以成为混音总线。
现在,假设您将两个3D声源发送到一条混音总线,您从总线得到的输出音频数据将会呈现多个声源/对象的叠加,而构成这个叠加的方向分量将会丢失。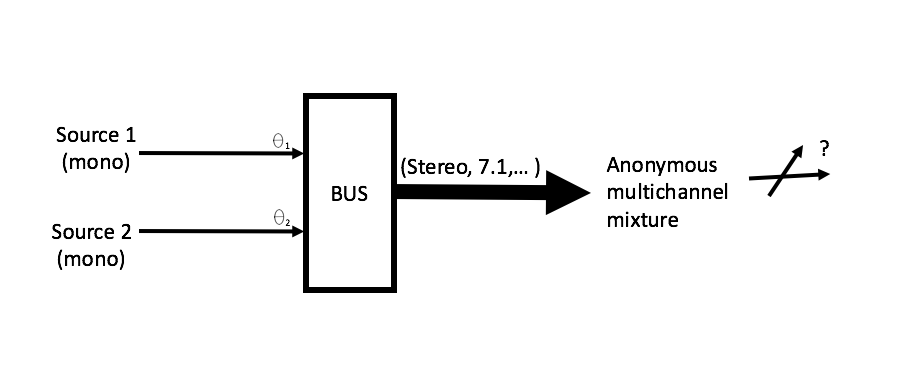
图1-两个入射角不同的声源被声像平移并混音到一条多声道总线上。声像平移意味着输入信号(此处表示为入射角Ɵi)的空间表示转换到输出信号(比如通过把信号分配到7.1扬声器设置的两个或更多声道上)的空间表示。输出就是声像平移对象的混合,并且不一定有一个确定的入射角(按照之前给的概念,输出不是一个对象)。
所以,基于对象的音频不兼容子混音,因为对象只存在于混音的上游,这一点可能限制声音设计师,让他们无法进行音频创作,而音频创作的很多手法一般都会用在子混音上。
案例分析
Wwise中的混音器插件界面是一种基于对象的插件架构,因为混音器插件需要独立的声源或“对象”来访问每个输入信号并生成双耳声音频。虽然它们看来是非常好的执行双耳声虚拟器的框架,但使用它们会导致对设计流程有所制约,因为基于对象的音频本身有局限性:
1.您不应该在双耳声信号上添加Effects(效果器)(至少不该添加非线性Effects, 如压缩器),因为它们可能会破坏您想用双耳声处理达到的空间音频感。

图2-错误地在混音器插件输出的双耳声信号下游添加压缩器Effect。
2.您不应该使用混音器插件上游的混音总线,因为缩混的结果将不再含有双耳声处理所需的3D信息。
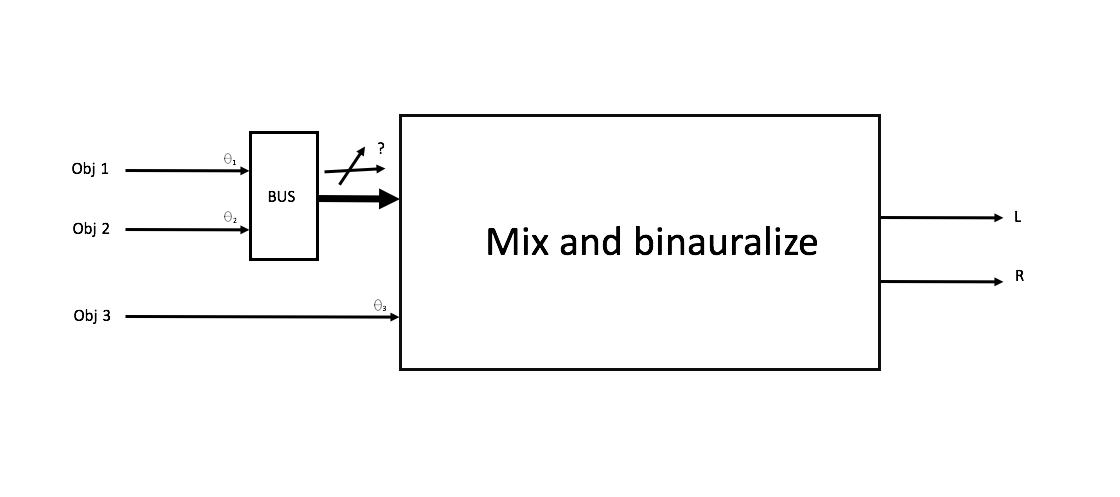 图3-混音器插件上游的对象混音。子混音信号不携带对象,因此不能被插件所双耳声化。
图3-混音器插件上游的对象混音。子混音信号不携带对象,因此不能被插件所双耳声化。
折衷
那么,如果我们能结合两者的长处该多好?我们能否以不错的空间精度渲染音频,同时又免受基于对象音频的缺点所困?请继续关注我们的博客,学习更多ambisonics的相关知识,也许能帮助您做到这一点!
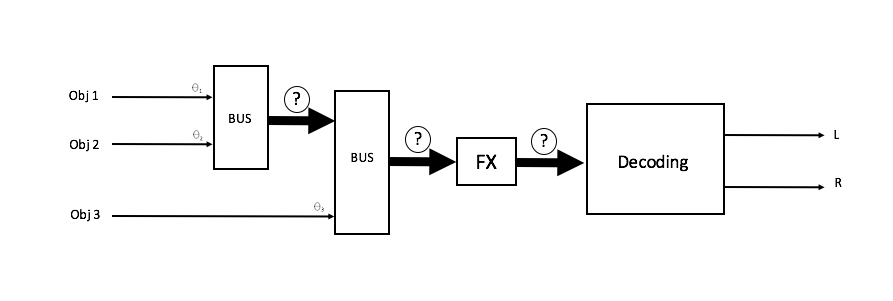
图4-对象被自由地缩混并声像平移到一个多声道空间音频表示上去,它能够传达所有成分的方向强度,并且能够通过添加Effects等来进行操纵。

LOUIS-XAVIER BUFFONI
主管, R&D - Audiokinetic
Xavier Buffoni在Audiokinetic负责领导空间音频研究。他拥有电器工程硕士学位并且偶尔会针对各种音频相关话题撰写文章、教授课程,如音乐、HDR动态混音等, 以及最近的基于对象的声像平移和ambisonics。Xavier曾在AES for Games,MIGS,以及其他行业会议中演讲。

评论