
欢迎继续阅读我们的 Impacter 插件系列博文。在前两篇博文中,我们主要介绍了插件的相关物理参数,以及如何与游戏的物理系统紧密结合。在这篇博文中,我们将着重探讨 Impacter 的交叉合成功能。
正如第一篇 Impacter 博文所述,我们可以自由组合不同声音的 Impact 和 Body 分层,以此来在一组音频样本的基础上生成各种变化版本。我们甚至在插件中实现了随机播放行为,以便设计师能够轻松操控这些变化版本。
我们可以从不同的声音提取所需的 Body 和 Impact 分层,进而借助交叉合成构建不同的声音版本来实现多样变化。
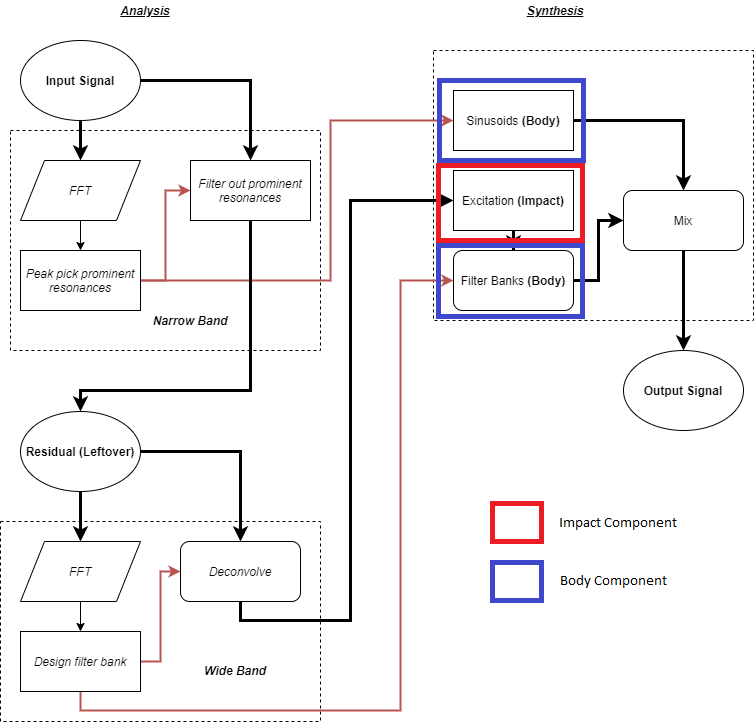
不过,交叉合成是一个非常宽泛的术语。为此,最好深入了解通过特定的 Impacter 交叉合成模型可以获得怎样的变化。一方面,我们希望向用户展示,通过 Impacter 生成的变化版本是切实、连贯的;这些变化版本不是多余的,其与原始声音存在某种内在关联。另一方面,也想向设计师保证,无需担心因为声音重复而破坏玩家的沉浸体验;虽然播放内容可以随机选择,但其跟原始声音绝非毫无区别。然而,把 Impacter 的交叉合成机制阐释清楚并不像听起来那么容易。
声音分析
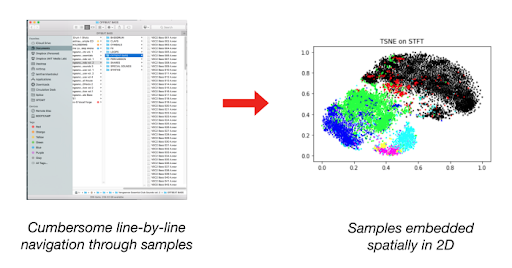
为方便调控交叉合成,Impacter 允许将加载到插件中的各个文件与加载的其他声音自由结合。比方说,12 个文件最多可有 144 种组合(用户可在 Source Editor 中弃用特定 Impact 和 Body 分层)。显然,144 个撞击声不是少数。别说试听了,看一眼都觉得眼花缭乱。这样会很难分辨声音之间的微妙差异。
比如:

说得简单点,逐个试听肯定是不行的。试想一下,听到第 87 个声音的时候谁能记得第 11 个声音听起来怎样。
那么,如何对如此大量的声音进行分析呢?
降维处理
作为一种应用广泛的音频分析技术,降维允许将大量声音映射到 2D 平面上以供察看。Lamtharn Hanoi Hantrakul 有关 Klustr 的博文中提到的工具 [1] 以及 ml4a (Machine Learning for Artists) 工具包中的 Audio t-SNE 查看器 [2] 便是很好的范例。
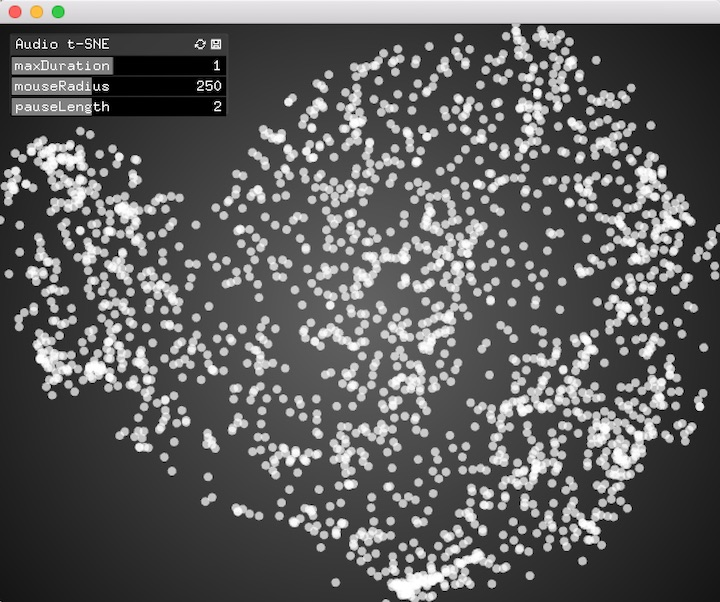
特性比较
在 2D 空间中对声音进行比较的方式有很多。就拿撞击声来说,其有一系列直观的潜在特性:自身物理特性(软硬、反弹、撞击)及被撞物体或表面的类型(玻璃、沙子、木头)。我们无法以数学形式明确定义所需声音的潜在特性,但可以设法从声音中提取各种音频特征来加以比较。
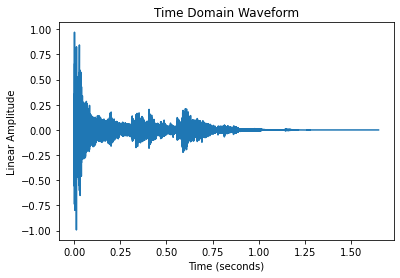
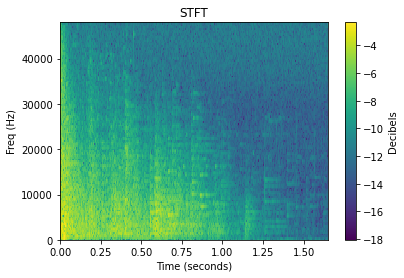
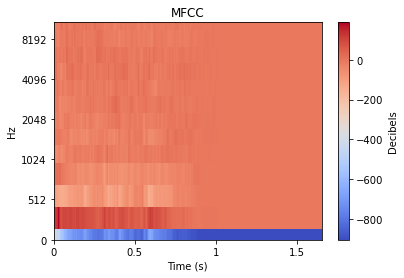
在处理音频时,以原始时域信号形式对不同声音进行比较的效果通常并不理想。好在有很多音频分析技术可供选择,来将声音转换为更具可比性的形式。在后文中可以看到,音频分析技术的选择将直接影响降维所生成的图表。
现在有大量关于各种转换方式的读物可供深入研究,不过在此仅展示如何将撞击类声音转换为视觉图表。此类转换一般会将 1D 音频信号扩展为 2D,并以颜色编码的方式来表示各个层次的值。
音频特征 |
|
 |
 |
 |
 |
降维最终提供的是对声音的视觉比较,藉此可直观地判断两个声音的 STFT 和 MFCC 差异。当然,它不像对不同声音(如鼓声、长号声、碎石声)的潜在特性进行比较那样具象化。不过,这些音频特征一样可以生成 2D 图表,其足以用来粗略估计声音之间的潜在差异。
降维技术
现在,我们选定了音频特征。在此基础上,可通过降维将与各个声音关联的一长串数值缩减为 2D 数组(如下图所示),进而轻松映射到二维平面的 X-Y 坐标上。不过,最重要的是我们想通过 2D 平面中各个声音之间的距离来反映其相似之处或微妙差异。在某种意义上,借助这种方式可以简化以上各种声音或特性之间的视觉比较。

一组 48k 采样率的声音(时长均为 2 秒):原本每个声音具有 96000 个数值,现在简化成了一个 2D 坐标组合
总的来说,整条“降维”管线大致如下:
| 声音波形 | 特征提取 | 降维处理 | 2D 图表 |
|
|
|
 |
视觉比较
要获得良好的降维处理结果,必须确保声音的数量足够多。幸运的是,我们手头就有个包含大量 Impacter 变化版本的 Wwise 工程:Impacter Unreal Demo(点此查看相关博文)!
Impacter 示例工程包含 289 个声音(涉及多个 Impacter 实例),最终共有 2295 个潜在变化版本可供分析。在实验当中,我们运行了离线版本的 Impacter 算法来生成所有这些变化版本,然后对比了各种音频特征提取方式的输入结果以及用来生成图表的降维算法。
既然知道声音和 Impacter 实例之间的对应关系,我们就可为每个 Impacter SFX 指派特定的颜色,并用不同形状对原始声音和变化版本进行区分。在以下示例中,我们用 X 表示原始输入声音,并用圆点表示通过 Impacter 生成的变化版本。颜色编码方便展示变化版本的连贯性:其与同一颜色的原始声音相近;同时也表明这些变化版本不是多余的:各个声音版本间不会完全重叠。
我们还尝试了其他一些音频特征和降维算法,并在这篇博文的末尾补充列出了相应的结果。在此,不妨先来看下比较理想的结果:
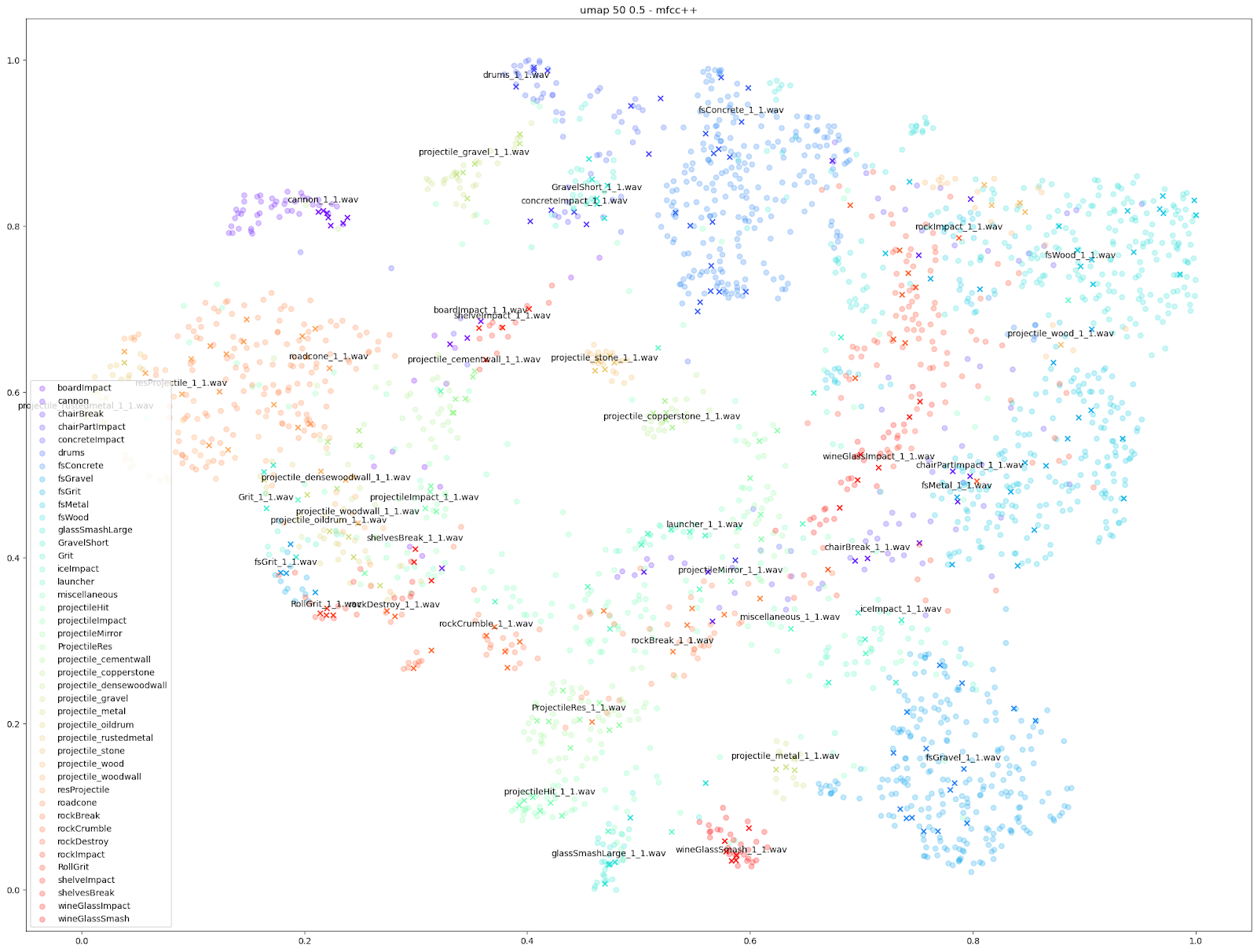
如上图所示,无论对于哪个 Impacter 实例(按颜色区分),原始声音和变化版本之间都存在异同的微妙平衡。Impacter 的作用并不只是增添随机性:颜色编码的声音最终还是会聚集在彼此附近,这正表明变化版本和原始声音之间是连贯的。
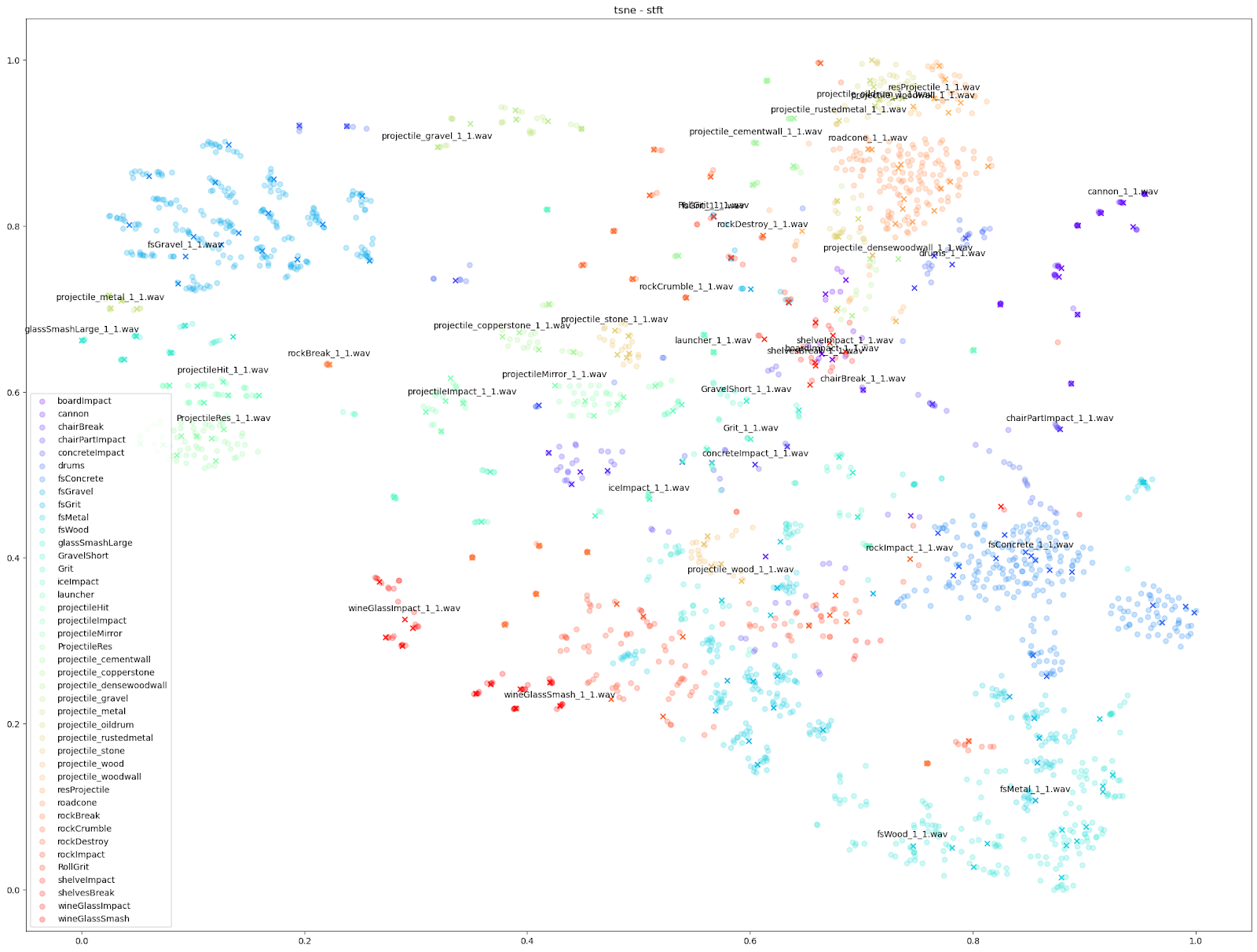
只要仔细察看一下基于 STFT 特征的 t-SNE 图表,就会发现每个 Impacter 声音的变化版本在 STFT 上都有一定程度的交融。拿右下角的 Concrete、Wood 和 Metal 声音来说,其原始声音附近的变化版本几乎是均匀分布的。这种情况是最为理想的。
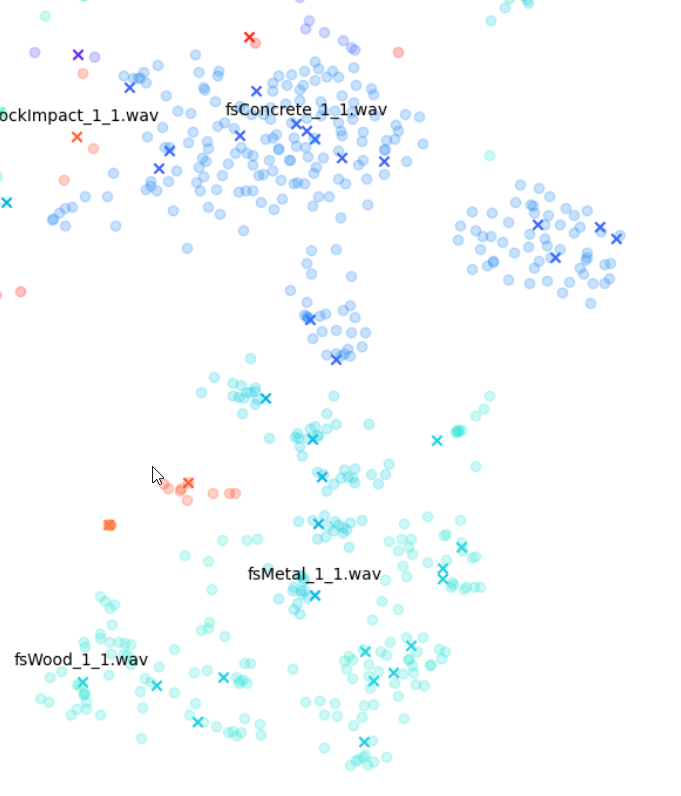
而对于 wineGlass 和 cannon 声音,很多圆点跟 X 都有交叠,表示这些变化版本在 STFT 上与原始声音非常相近。
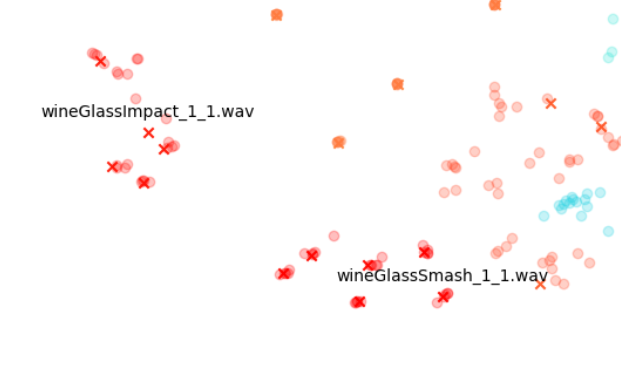
相较而言,左上角 Gravel 声音的情形算是介于两者之间:一方面,变化版本跟原始声音有明显差异;另一方面,各个群集之间又是相互分开的。
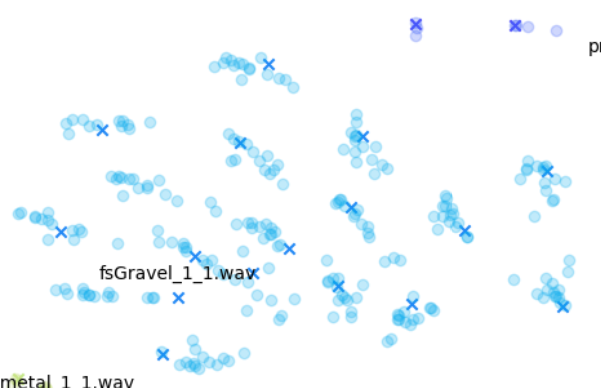
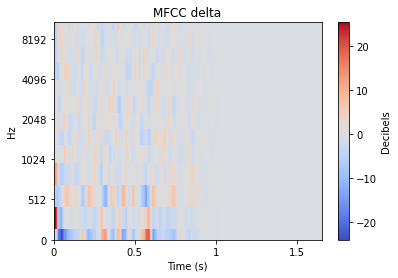
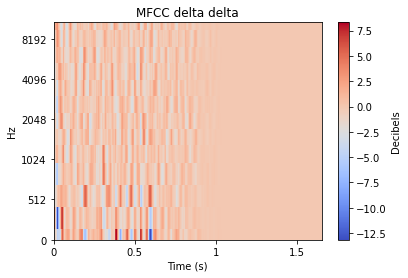
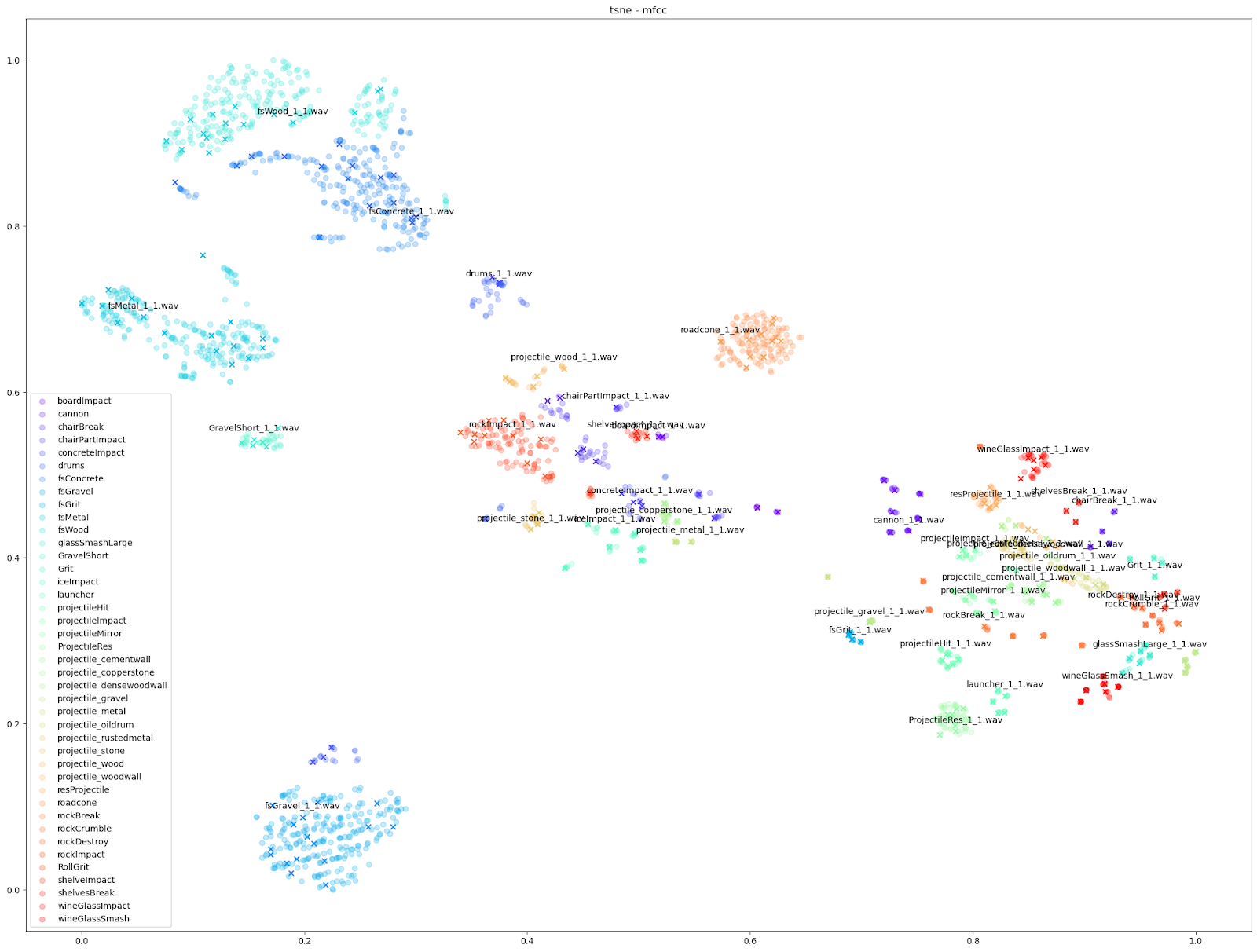
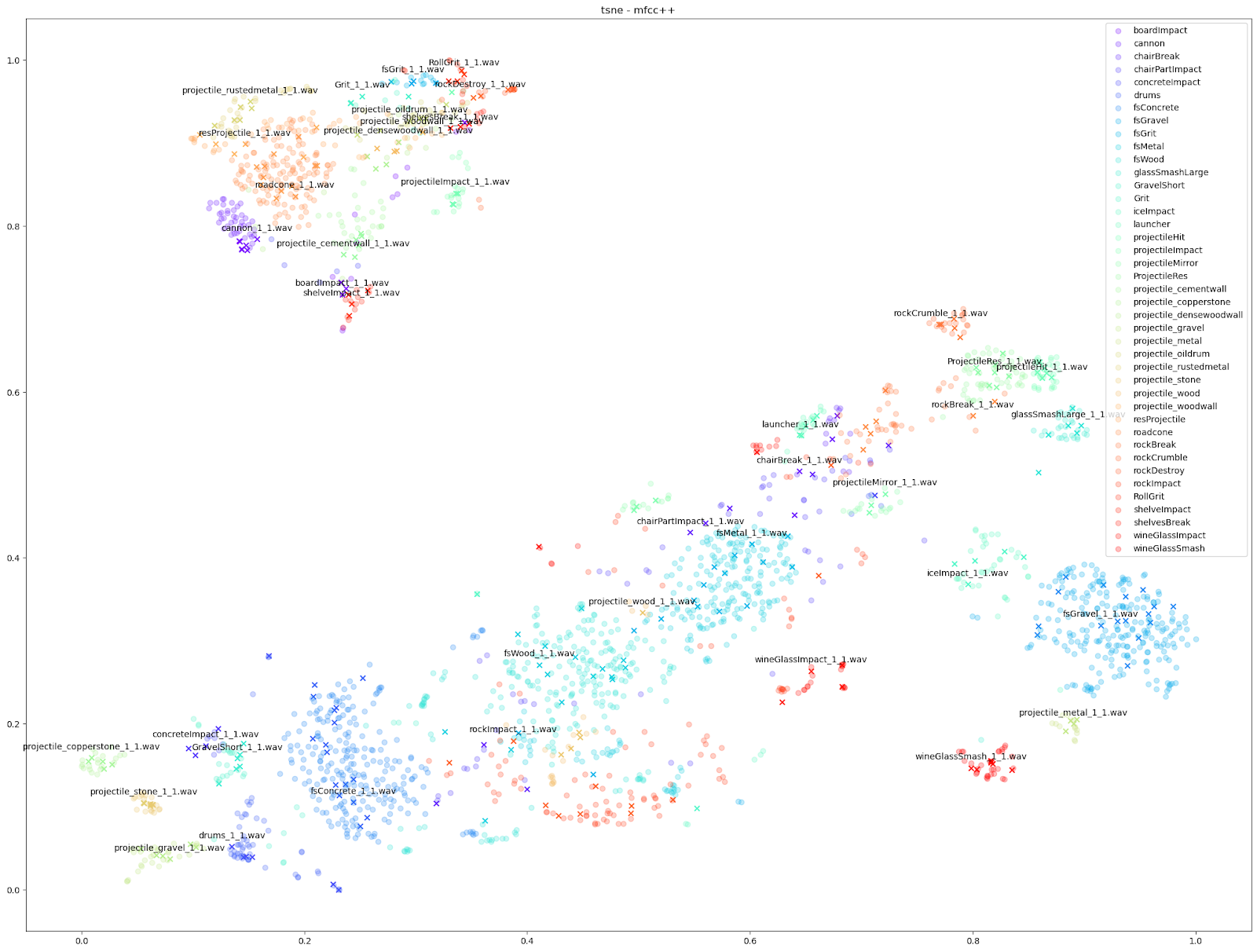
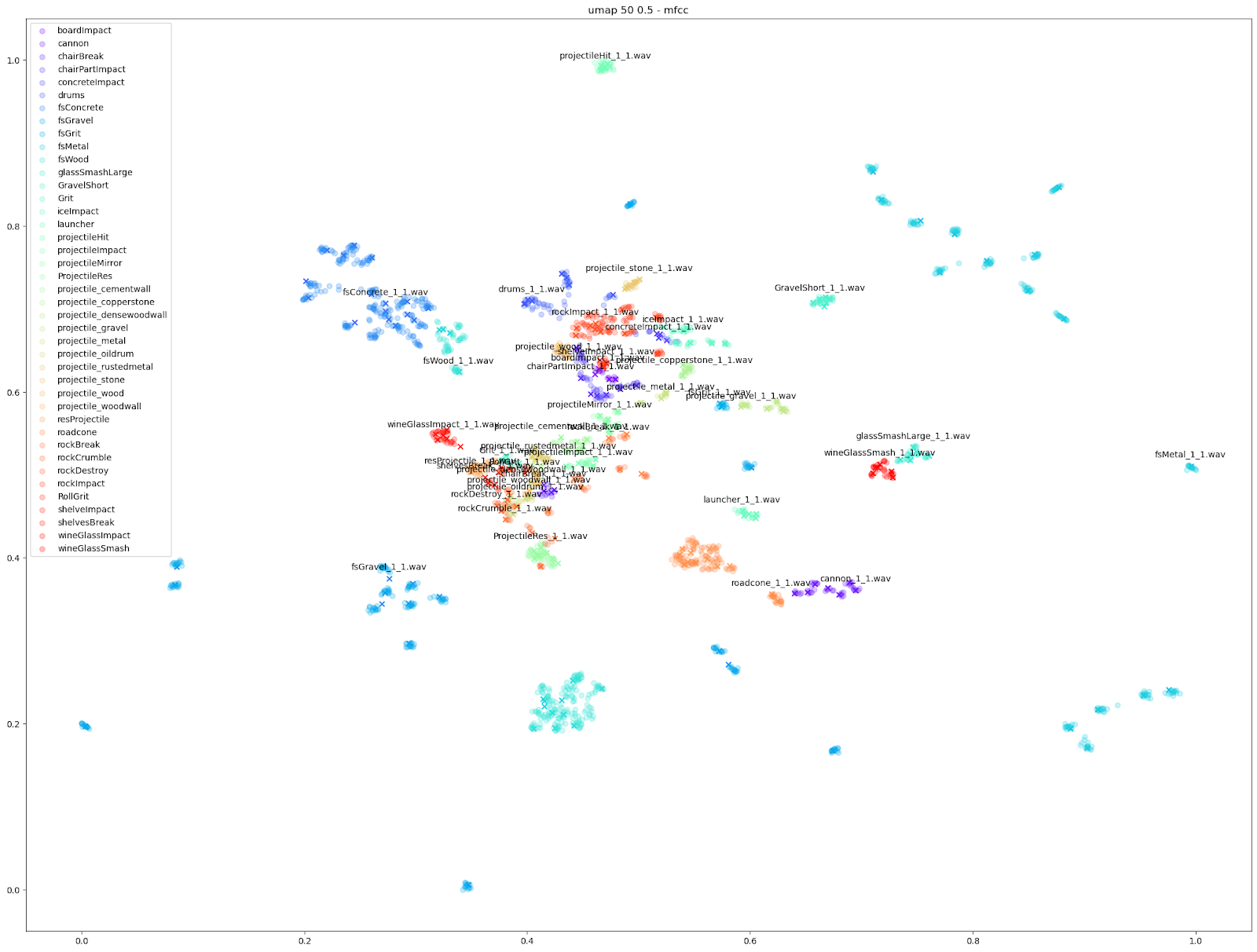
除此之外,我们还可以使用基于其他音频特征(如 mfcc++)的图表来突显更为细微的差异。通过加入一阶和二阶 delta [3] 差值(即 mfcc++ 中的 ++),可将 STFT 图表中原本靠得较近的群集(如 wineGlass)分散开来。
.png)
现在,我们生成了图表来在 2D 空间中突显声音之间的差异。藉此,可一次性查看所有变化版本,甚至放大特定声音来分辨局部差异。不但看上去非常整洁,同时也很好地展示了 Impacter 的工作机制。
Impacter 是个对撞击声进行建模的分析与合成系统,不过各种算法对不同输入声音的建模效果有好有差。借助这些图表,我们可以粗略判断 Impacter 对某个声音的建模效果。正如上图所示,wineGlass 声音版本之间的差异相对较小。因此我们可以说,Impacter 对它的建模效果不如 Metal、Wood 和 Concrete 声音那样理想。虽然听上去简单明了,其实蕴含了一个道理:在选择使用 Impacter 处理的声音时,要明白交叉合成功能的效果跟声音本身密切相关。简而言之:有些声音会有更多变化,有些则没有那么多变化!
当然,这些都不是对 Impacter 的适用性的严格论证,只是展示如何直观地呈现大量声音之间的各种差异,同时借此机会验证一下各种精妙的数据可视化技术。
其他问题
除此之外,我们还可通过降维来做其他比较,以此直观地展示 Impacter 的功用。为此,我们尝试了以视觉形式呈现由 88 个不同 tile 脚步声生成的变化版本,最终加起来一共获得了 7744 个 tile 声音。只要仔细察看一下基于 mfcc++ 特征的 UMAP 图表,就会发现所有 Impacter 声音的变化版本都落在了原始声音的中间。因此,从这 88 个脚步声中选取一部分放到 Impacter 中可以重构一个范围相近的图表。比如,第二张图便展示了由其中 22 个脚步声生成的变化版本。
| 由 88 个脚步声生成的变化版本 | 由其中 22 个脚步声生成的变化版本 |
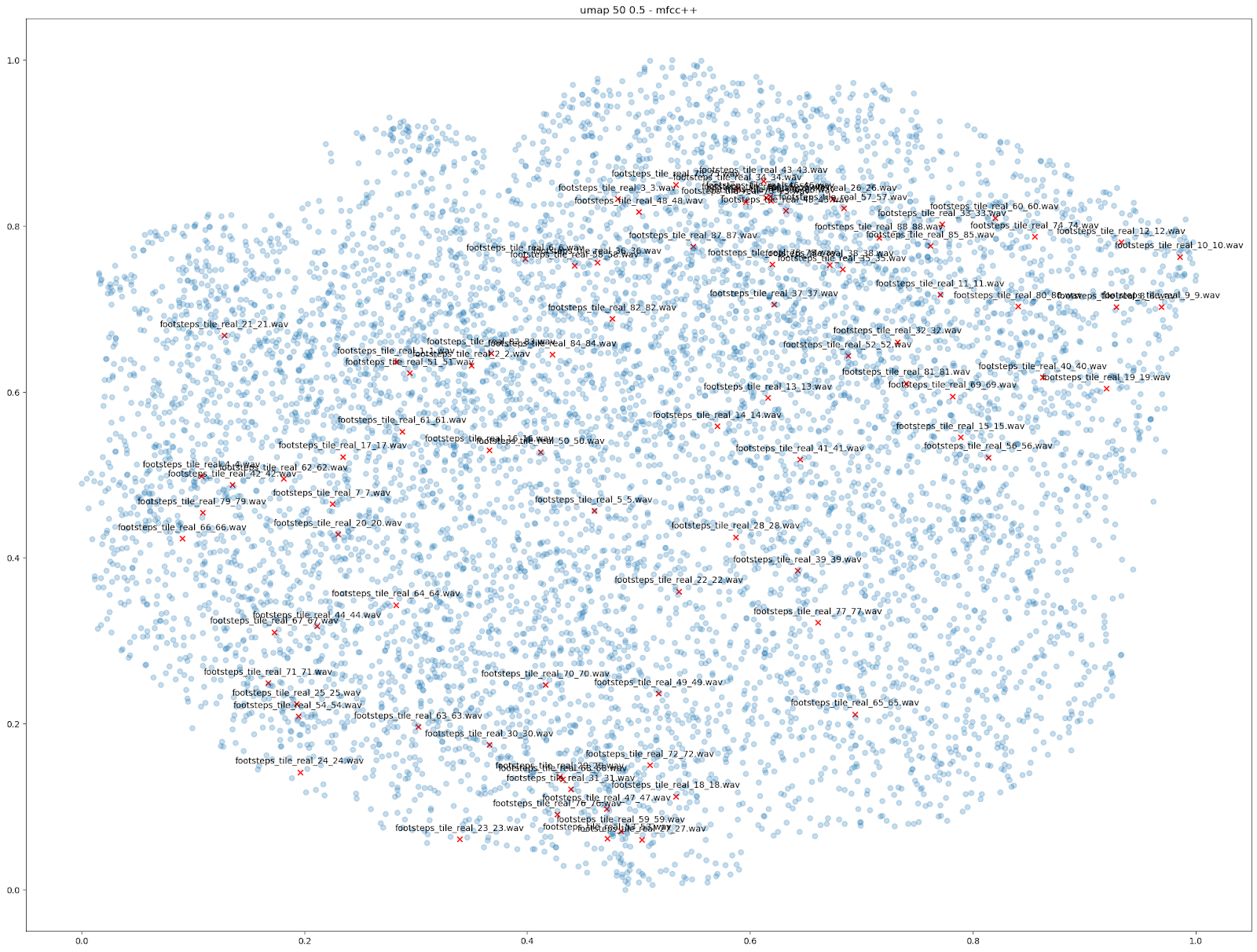 |
|
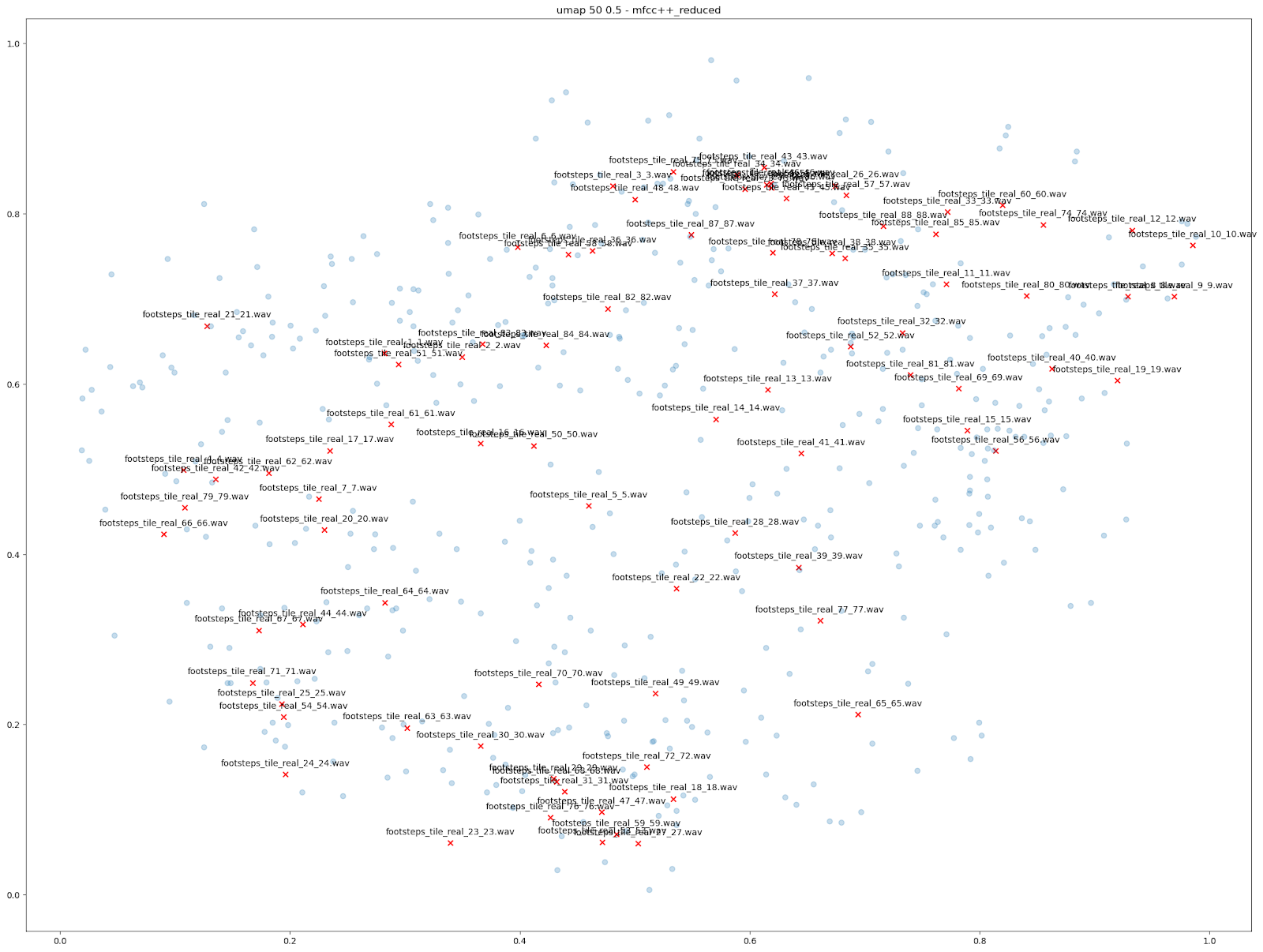
在图片上右键单击“新建标签页打开图像”查看大图
结语
希望本文有助于解答关于如何利用 Impacter 交叉合成算法生成多样变化的问题。就像前面说的,在此并不是要严格论证 Impacter 的适用性,只是直观地呈现插件可能生成的大量声音,来让各位更好地了解 Impacter 的实际用途。
更多细节…
数据格式
降维算法只是单纯地接收一系列数组或向量。其既不讲求输入数据的类型,也不限定 2D 输入数据的维度(如 STFT 或 MFCC)。为此,我们其实可以对 2D 数据进行扁平化处理,甚至将前述多项特征并成 2D 数组来提供给算法。
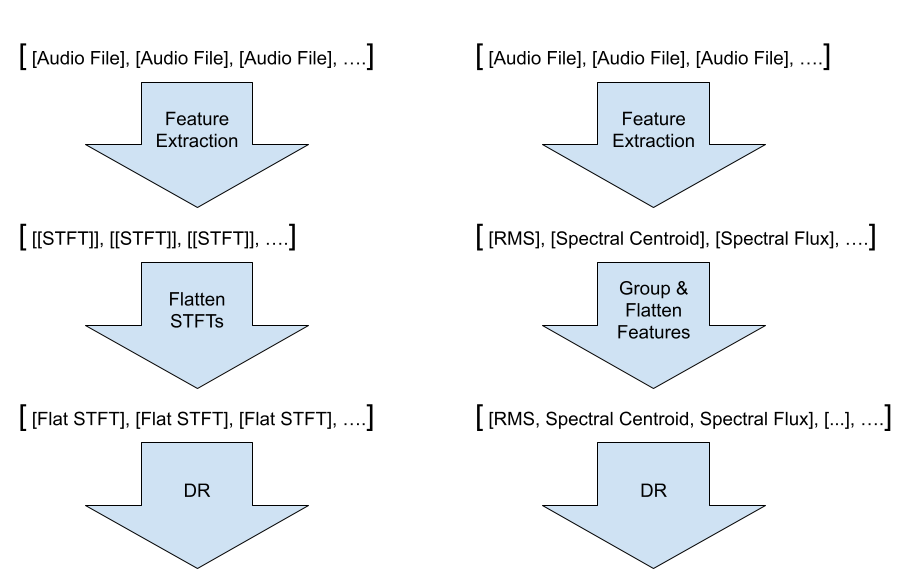
降维算法
现在有很多降维算法只是单纯地接收一系列数组或向量(也就是我们在第一步中提取的各项音频特征)。
Python 中的 sklearn 和 umap-learn 数据包(可通过 pip 下载安装)整合了各种实用降维算法。很多文章都讲过这些算法的原理和用途。但本文篇幅有限,在此不一一阐释。如果想了解其中详情,请点击文末链接查看。
t-distributed Stochastic Neighbor Embedding (t-SNE)
from sklearn.manifold import TSNE
tsne = TSNE(
n_components=tsne_dimensions,
learning_rate=200,
perplexity=tsne_perplexity,
verbose=2,
angle=0.1).fit_transform(data)
Uniform Manifold Approximation and Projection (UMAP)
import umapumap = umap.UMAP(
n_neighbors=50,min_dist=0.5,n_components=tsne_dimensions,metric='correlation').fit_transform(data)
Principal Component Analysis (PCA)
from sklearn.decomposition import PCApca= PCA(n_components=tsne_dimensions).fit_transform(data)
Multidimensional Scaling (MDS)
from sklearn.manifold import MDSmds = MDS(
n_components=tsne_dimensions,verbose=2,max_iter=10000).fit_transform(data)
全部结果
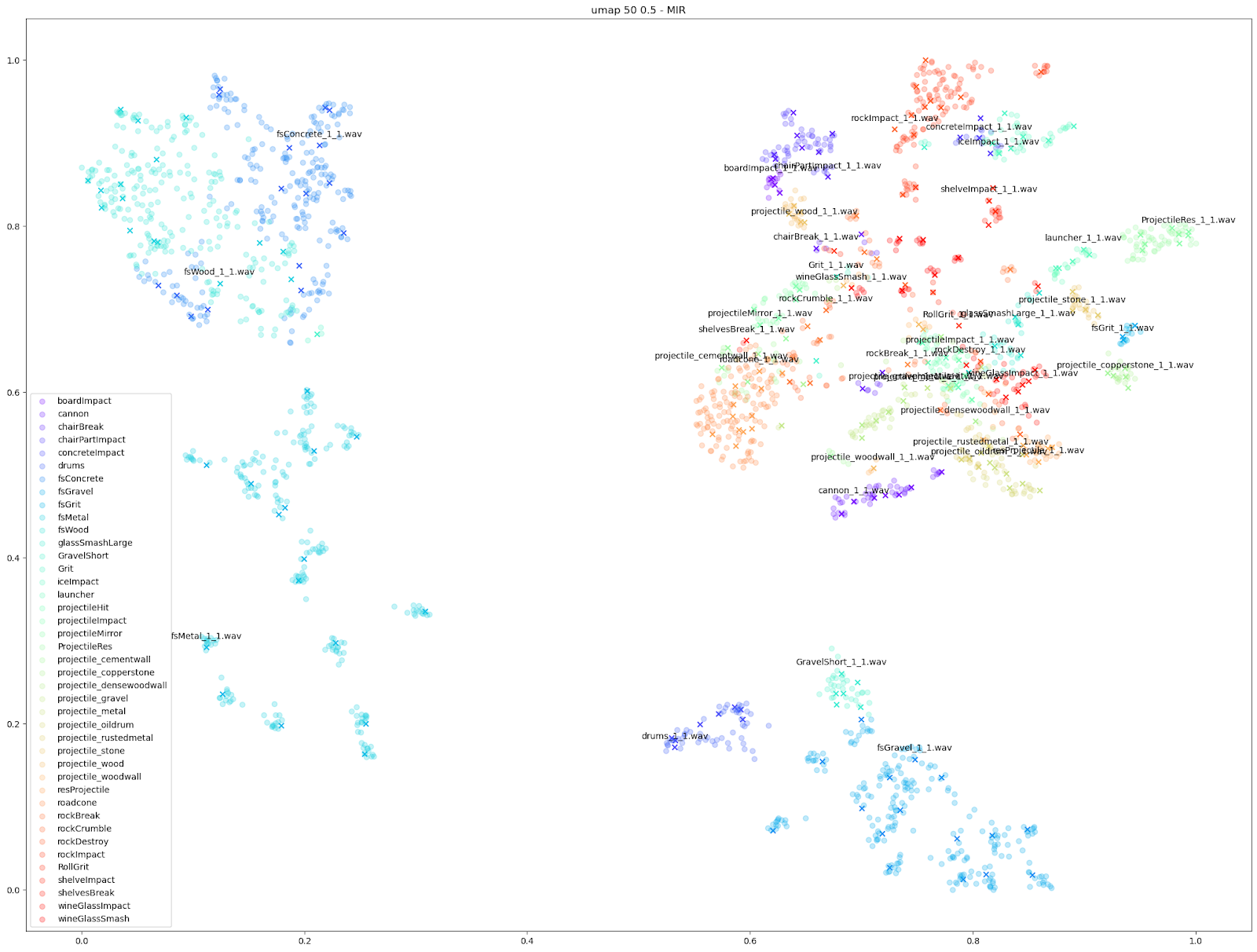
在 Impacter 的实验当中,我们对以上四种降维算法做了比较。为此,我们在各种算法中代入了不同的音频特征:STFT、mfcc、mfcc++ [3] 及 MIR(RMS、Spectral Centroid、Spectral Crest、Spectral Flux、Spectral Rolloff、Zero Crossing Rate)。
| STFT | mfcc | mfcc++ | MDS | |
| t-SNE | 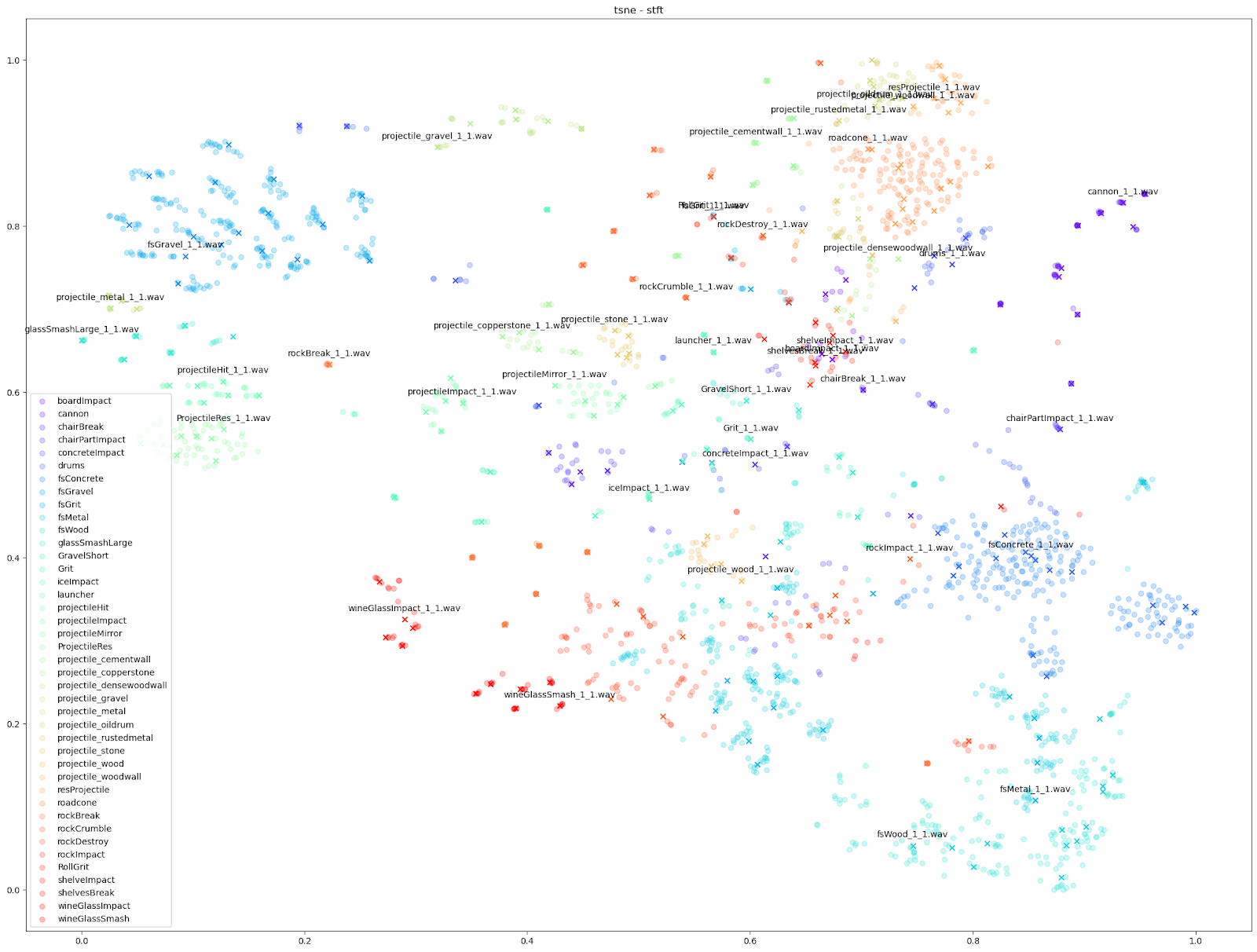 |
 |
 |
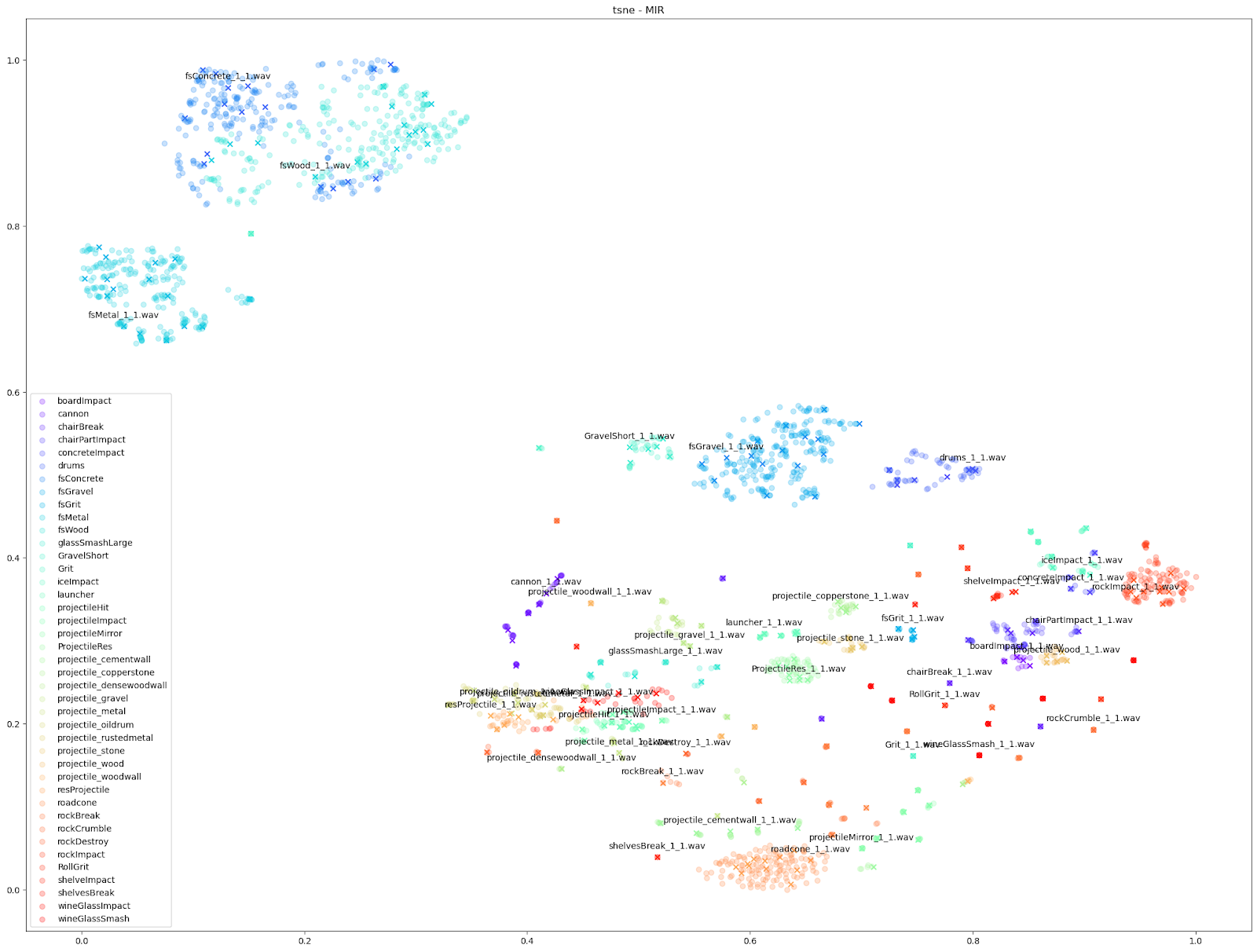 |
| MDS | 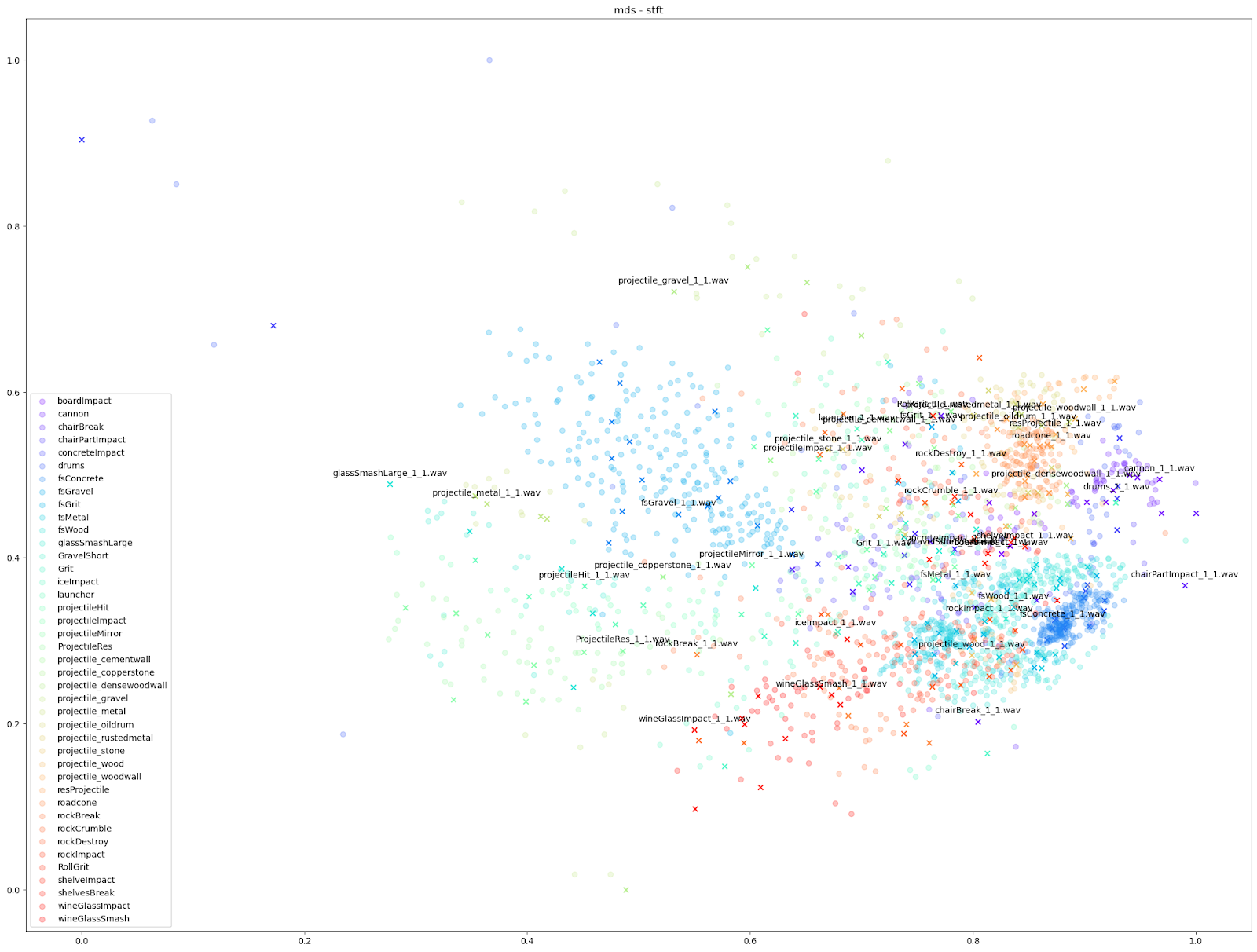 |
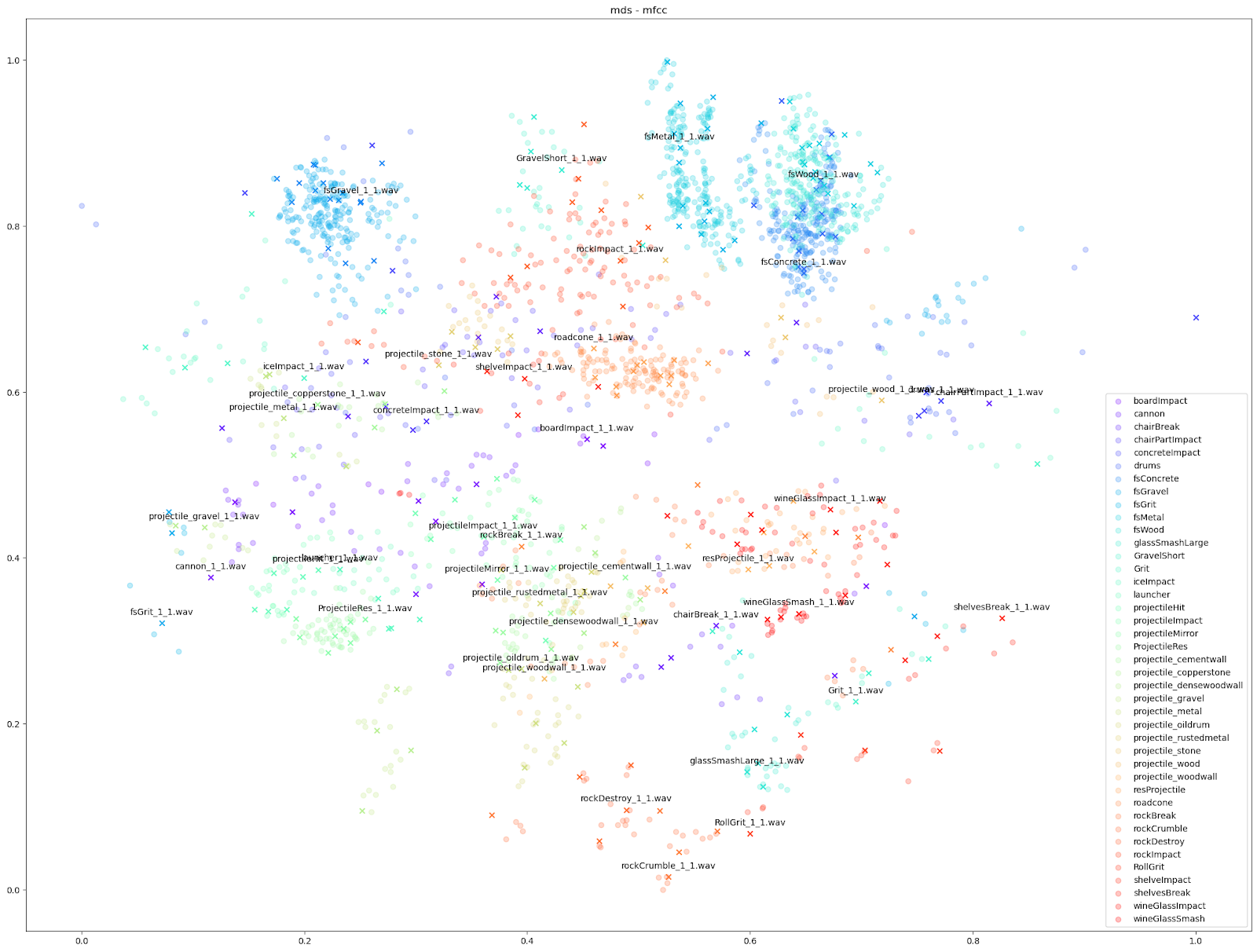 |
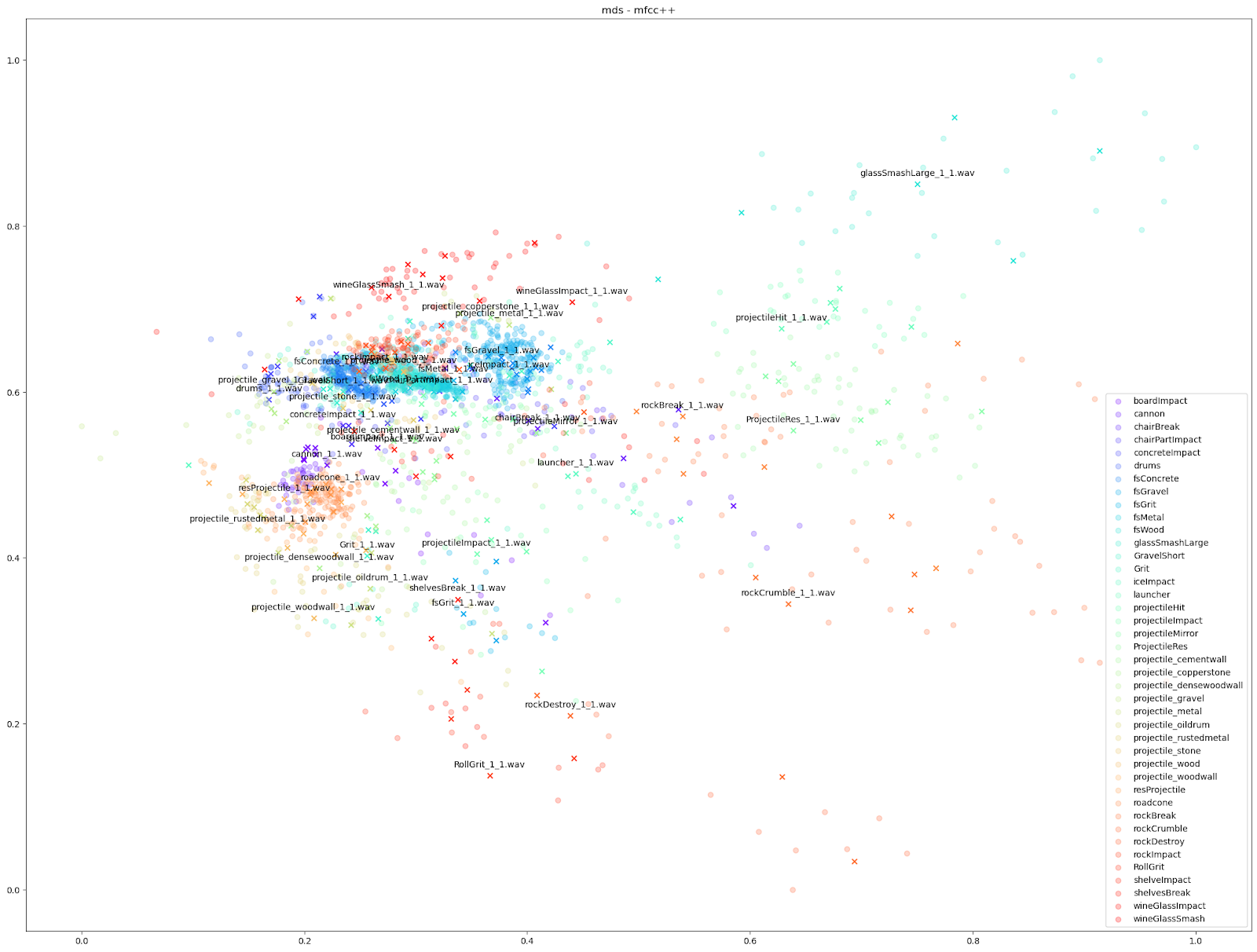 |
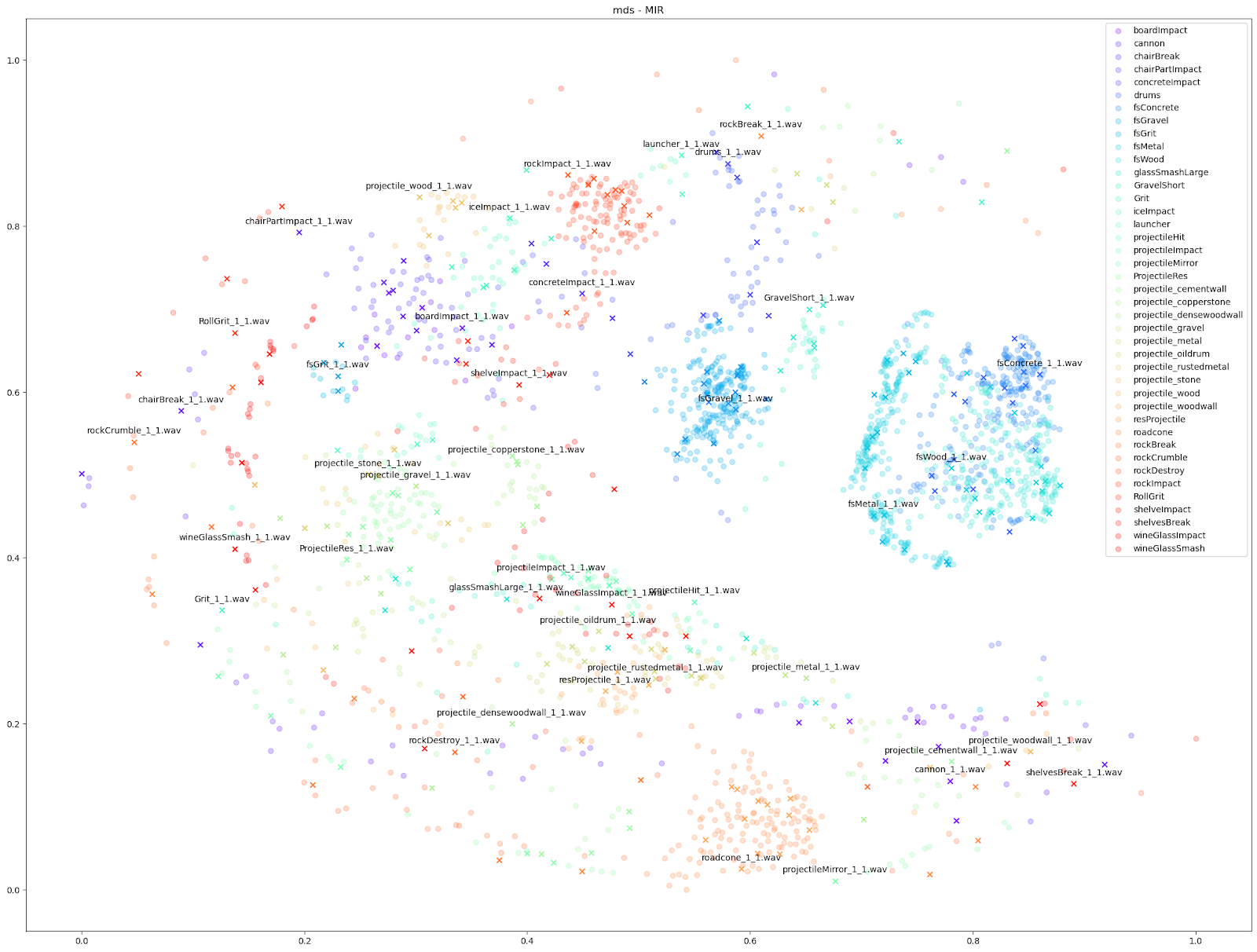 |
| PCA | 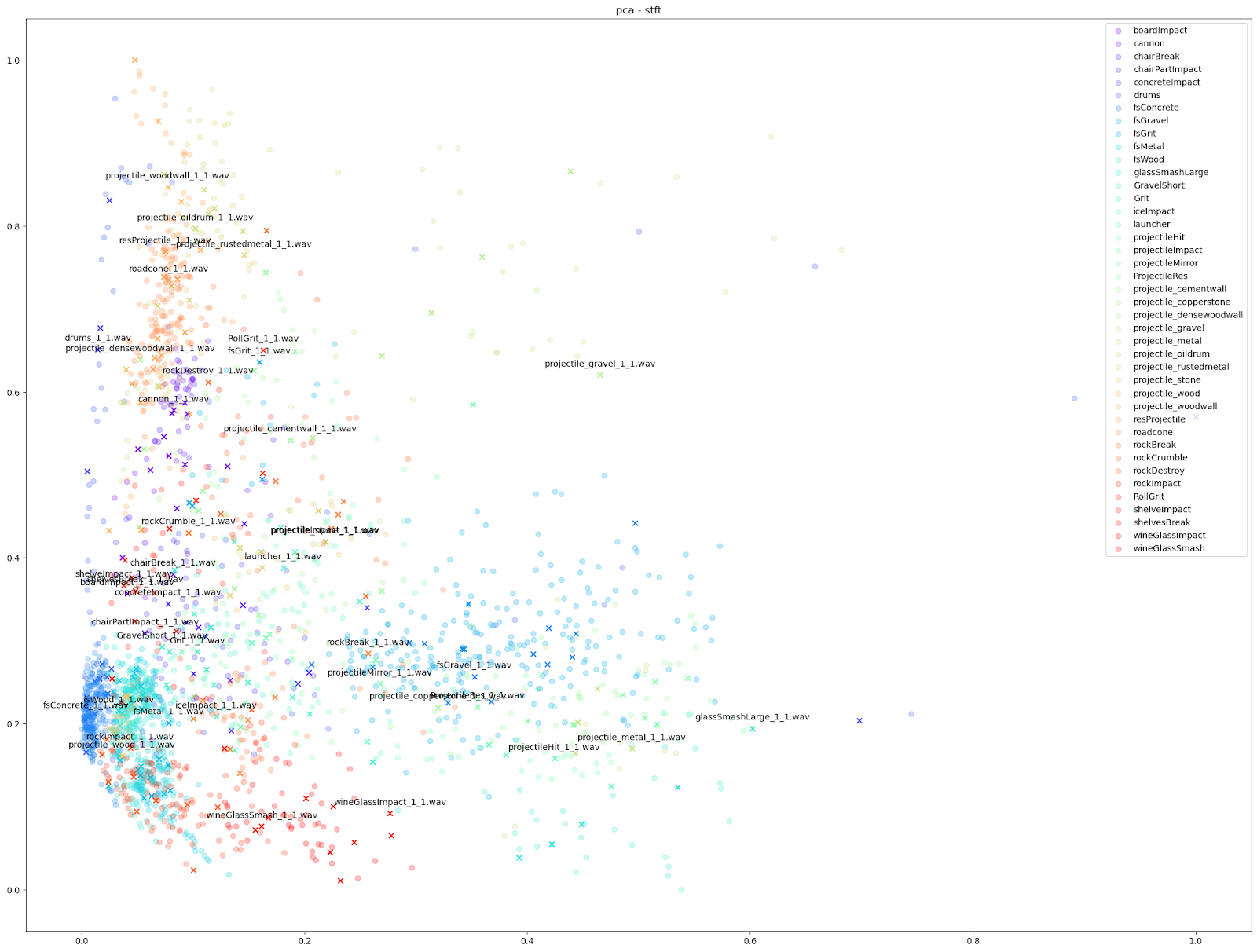 |
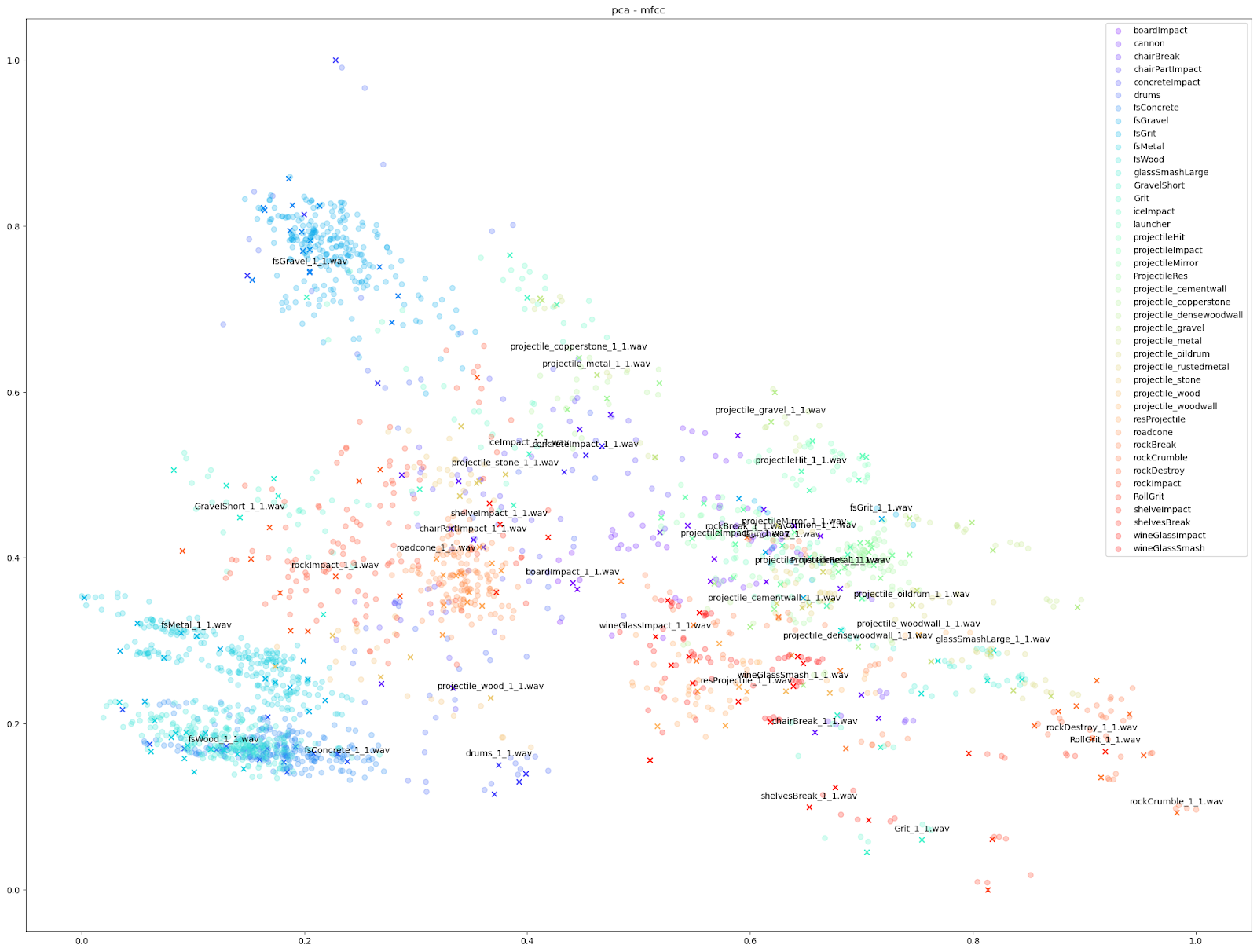 |
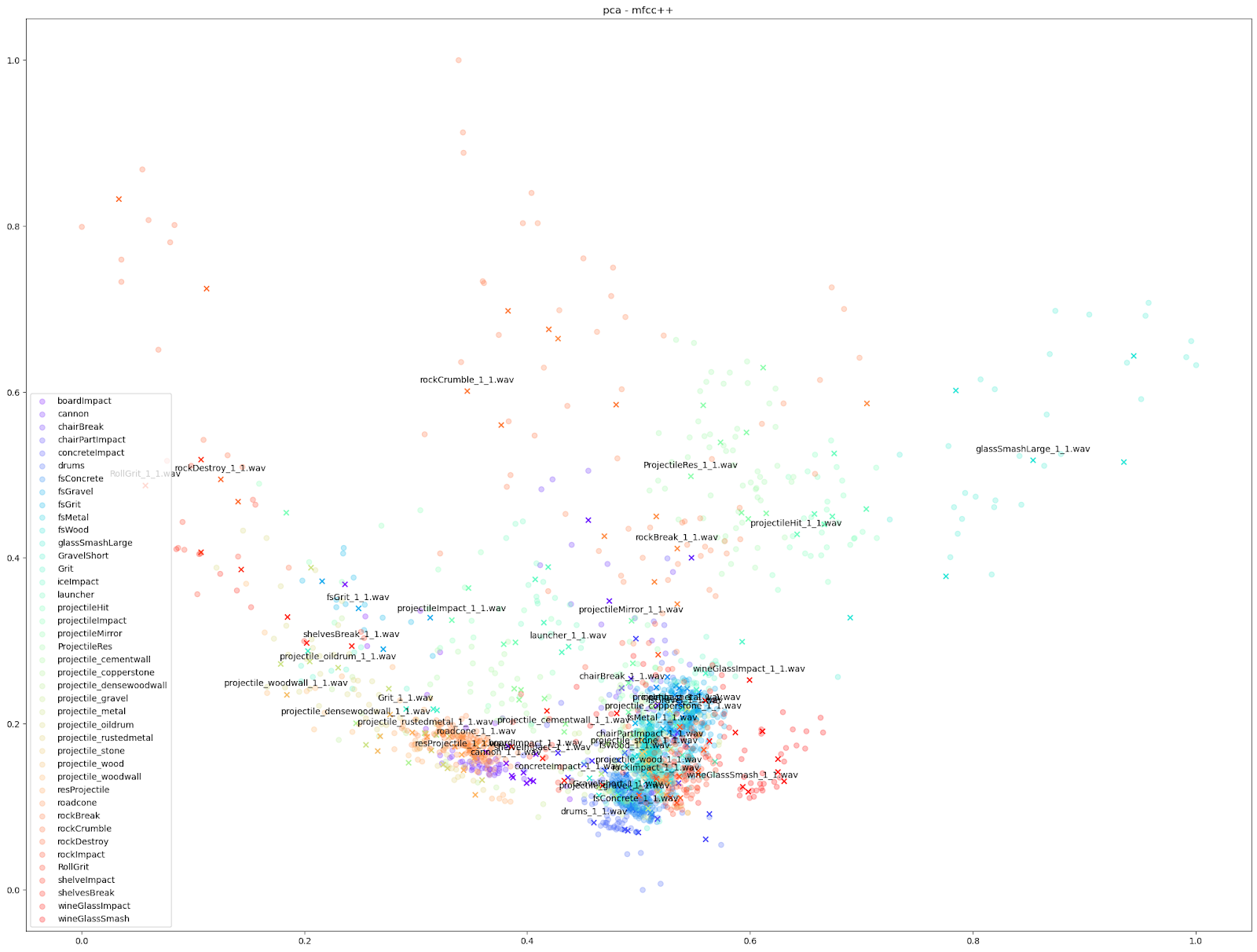 |
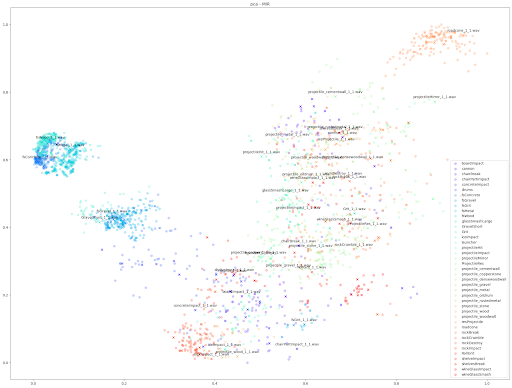 |
| UMAP 50 0.5 | 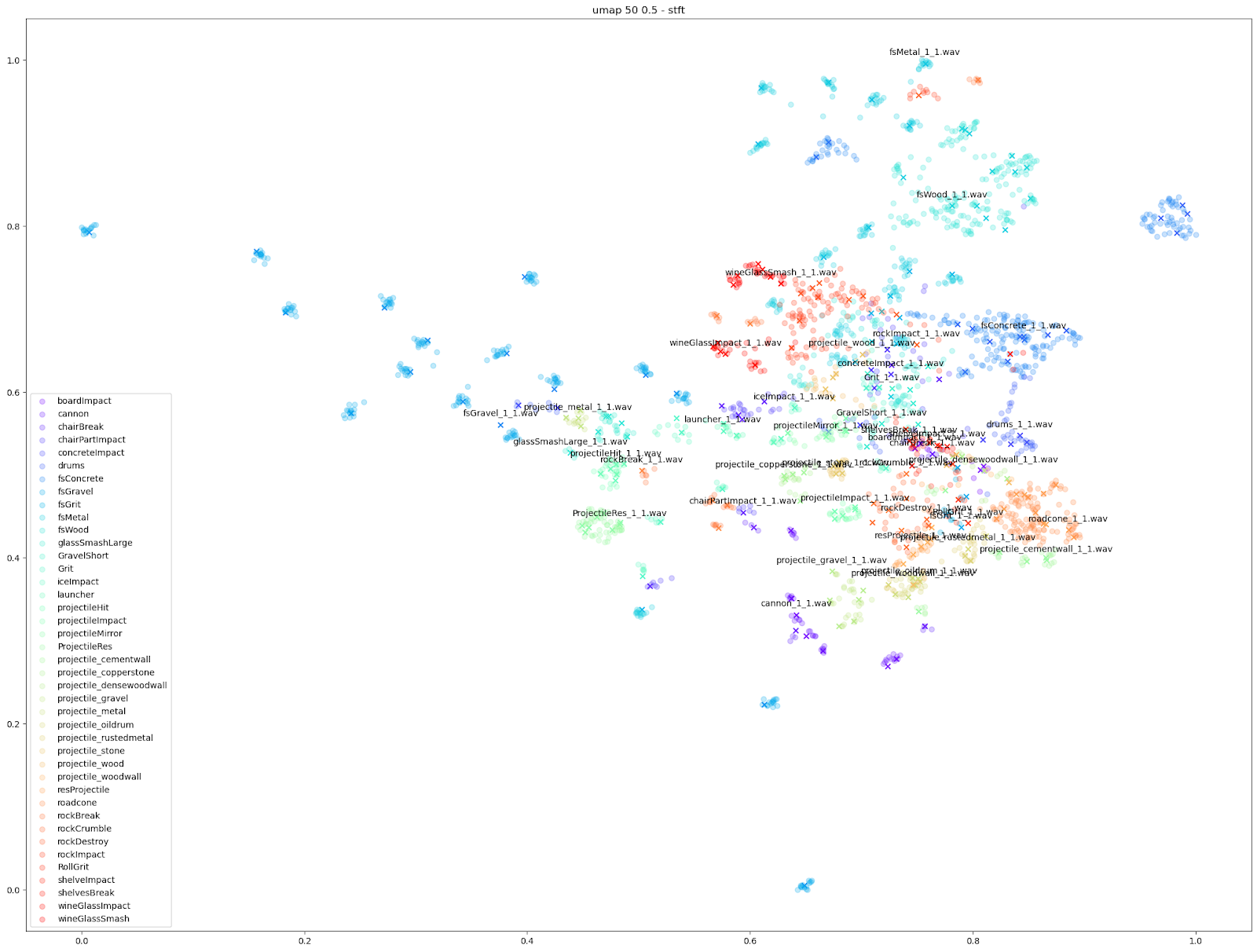 |
 |
.png) |
 |
在图片上右键单击“新建标签页打开图像”查看大图
如上所示,我们发现基于 STFT 和 mfcc++ 的 UMAP 和 t-SNE 图表最为实用。
参考文献:
[1] - Hantrakul, L. “H. (2017, December 31). klustr: a tool for dimensionality reduction and visualization of large audio datasets. Medium. https://medium.com/@hanoi7/klustr-a-tool-for-dimensionality-reduction-and-visualization-of-large-audio-datasets-c3e958c0856c
[2] - Audio t-SNE. https://ml4a.github.io/guides/AudioTSNEViewer/
[3] -Bäckström, T. (2019, April 16). Deltas and Delta-deltas. Aalto University Wiki. https://wiki.aalto.fi/display/ITSP/Deltas+and+Delta-deltas

评论