
Wwise 中针对 Spatial Audio 所作的改进 – 第 1 部分:距离建模和早期反射
Wwise 中针对 Spatial Audio 所作的改进 – 第 2 部分:衍射
在本系列博文前两部分中,我们探讨了设计师如何模拟与早期反射相关的声学现象,并利用 Wwise Spatial Audio 来根据需要调节所构建的音频。接下来,我们说说如何对后期混响执行同样的操作。
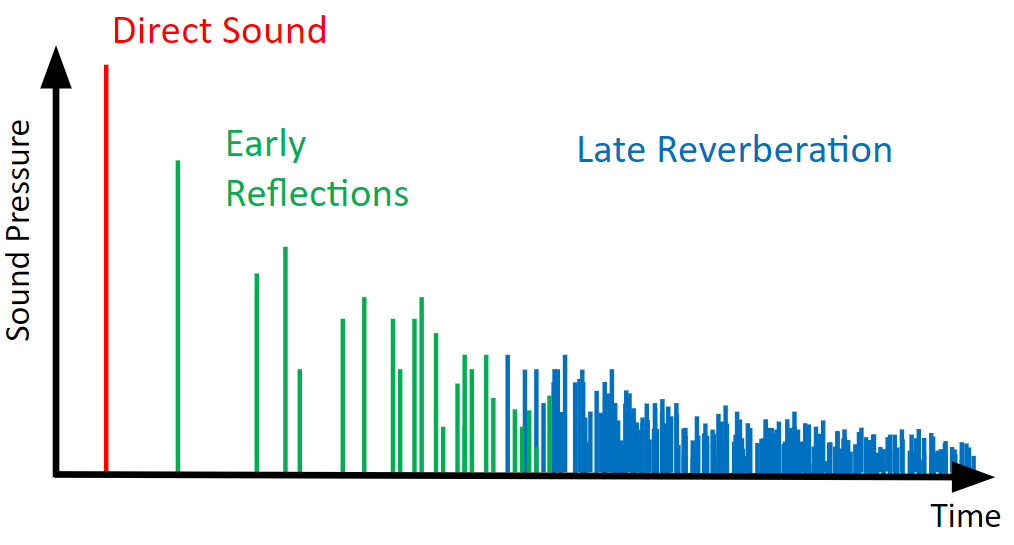
图 1 - 冲激响应 (IR) [20]
利用 Room 和 Portal 发送环境信息
Wwise Spatial Audio 对后期混响的设计跟使用 Auxiliary Send 设定环境的传统方法很像,两者都是通过调节混响效果器的设置来确保与游戏的画面效果和美学风格协调一致。只不过对前者来说,引擎会自动实施空间化处理,并借助 Room 和 Portal 加以实现。
利用传统的 Auxiliary Send 方法,可将带有混响效果器的 Auxiliary Bus 指派给各种环境或环境类型,并将声部发送到环境或听者所属的总线。Room 对此做了进一步的扩展。在设有 Room 和 Portal 时,可将 Portal 用作两个 Room 之间的连通媒介。声音会激励相应的 Room ,并通过 Room 和 Portal 网络传向听者。从信号流的角度来说,声音会被发送到相应 Room 的 Auxiliary Bus,并经由 Auxiliary Send 链路抵达听者。在这当中,Portal 会负责处理相邻 Room 混响声场的衍射、空间化和散布。我们团队的内森 (Nathan) 在其博文中对这一系统进行了简要的阐述 [21]。
Spatial Audio 的两种范式
本系列博文前两部分中提到的射线投射引擎和上文所述 Room 和 Portal 系统遵循两种不同的范式,每一种都有各自的设计工作流程和性能考量因素。具体来说,前一系统遵循“通过几何构造驱动声学模拟”范式,后一系统遵循“利用声学参数控制混响效果器”范式。
通过几何构造驱动声学模拟
此范式主要涉及三角形和材料。藉此,设计师可在 Wwise 中控制材料吸收以及距离曲线和衍射曲线。
在采用基于射线的方法渲染后期混响时,计算的复杂程度会呈指数级增加。事实上,如果只是对这种方法进行简单的扩展,恐怕连实现后期混响都无法做到。因为其反射的密度太低,会导致声音出现颗粒化。在现实生活中,“在达到一定反射阶数之后,表面散射和边缘衍射往往会盖过镜面反射”[22]。也就是说,最终抵达听者的波前要比简化射线模型预测的多得多,也比其所用简化几何构造允许的多得多。
通过将细节层次提高到微观层面来解决这一难题是不现实的。相反,基于射线的方法通常会向其模型添加随机元素以获得更为逼真的效果,就像图形会借助于着色器和漫反射光照技术而非仅靠 Mesh 来增强画面一样。
音频 1 - 仅包含 16 阶镜面反射的 IR。为此,需针对略有梯度的长方体禁用衍射,并将数字脉冲馈送到 Wwise Reflect 中。
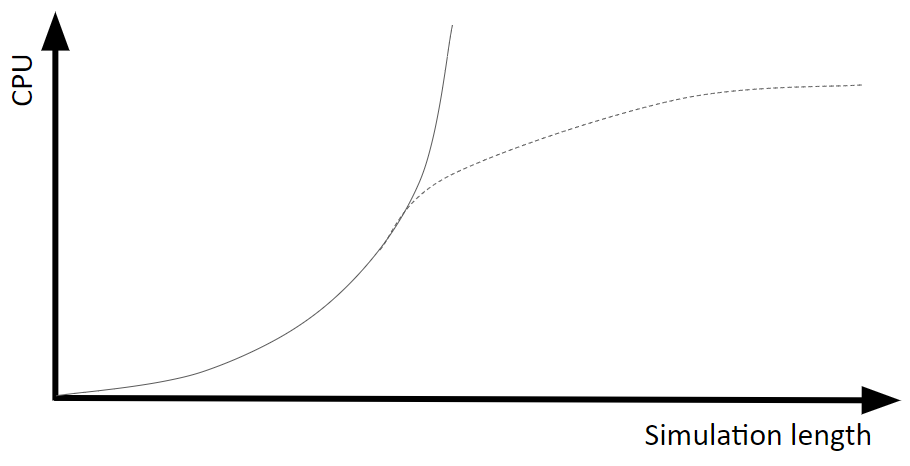
图 2 - CPU 成本与模拟长度。模拟长度与混响时间有着松散的联系。不过,这也意味着射线要与更多的几何构造交互。实线代表直接取值法。可见准确计算后期混响的成本会呈指数级增加。虚线代表近似取值法。可见在实践中实施粗略计算有助合理控制性能。
Oculus 采用的声音传播技术便遵循此范式。确切地说,就是利用射线追踪来计算高阶现象,然后一并渲染早期反射和后期混响 [23]。据估计,其应该还使用了多种技术来避免因后者而导致成本呈指数级增加。藉此,设计师只需通过设定材料的属性来对声音进行微调即可。
利用声学参数控制混响效果器
此范式主要涉及声学参数,其会利用混响效果器来渲染 IR。藉此,设计师可控制混响效果器设置和发送电平,并结合声学参数来在运行时调节所述设置。这种方法的计算成本相对较低。因为大部分 CPU 资源会用于处理混响效果器,而不是用来计算声音传播。
从定义上来看,声学参数取决于游戏中听者或发声体的位置。但是,其性质和获取方式对不同解决方案来说存在很大差异。所需的空间化采样也不尽相同,不过其通常遵循以下经验法则:相较于后期混响,在处理早期反射时需要将更多信息告知混响效果器。
事实上,早期反射有较强的方向性,其由特定的音频事件构成。这种方向性在很大程度上取决于环境中发声体和听者的位置。比如,直达(衍射)路径的方向性完全取决于两者的相对位置以及是否存在障碍物。早期反射的方向性也是如此,但同时跟距离附近墙壁远近有关。与之相比,后期混响的方向性较弱,其由看似随机的波前构成。因而,只需对空间进行粗略的采样即可。
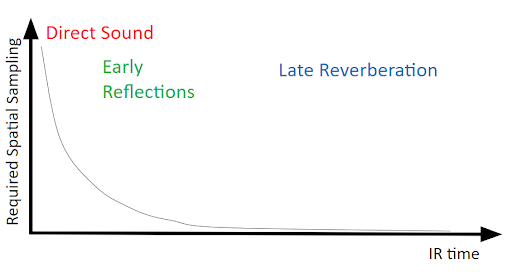
图 3 - 声学参数的空间采样密度。通过几何构造相关声学参数来控制混响效果器,并藉此精确渲染直达声、早期反射和后期混响。在发声体和听者位于同一 Room/环境且距离较近的情况下,早期反射需要比后期混响更为精细的采样,因为它们的位置对后者并不会产生太大影响。空间采样密度高并不意味着一定会增加 CPU 成本,但肯定会消耗更多内存资源并加重参数采样负担。
Microsoft 开发的 Project Acoustics 解决方案便通过几何构造相关声学参数控制混响效果器。该解决方案可自动对参数进行采样,并采用基于波的方法来离线模拟声音传播。进而,利用提取的参数驱动混响效果器和发送电平 [24]。因为其全面涵盖了直达声、早期反射和后期混响,所以要在几分之一米的精细网格上针对每个发声体-听者对的可能位置计算一组不同的参数。
相比之下,Wwise Spatial Audio Room 的声学参数主要涉及要将哪条 Auxiliary Bus 指派给给定的 Room。目前的声学参数并不是通过几何构造自动推导出来的,而是由设计师依据对几何构造的声学特性手动指派的。另外,每个 Room 只有一组对应的声学参数。因此,正如前面所说的那样,其空间采样是非常粗略的。
Wwise Spatial Audio 结合运用两种范式
下表对前面所说的内容进行了总结。
| 通过几何构造驱动声学模拟 | 利用声学参数控制混响效果器 | |
| 设计师控制 | 距离曲线、衍射曲线、材料吸收 | 混响设置和发送电平 |
| 引擎输入 | 几何构造和标定材料 | 声学参数(以某种方式从几何构造提取) |
| 成本 | CPU 成本相对较高,并会随着模拟长度呈指数级增加 | 运行时成本较低;为了捕获早期反射,参数采样需要更加精细 |
表 1 - 对比两种范式:“通过几何构造驱动声学模拟”和“利用声学参数控制混响效果器”
Wwise Spatial Audio 设法结合了这两种范式的优势。一方面,“利用声学参数控制混响效果器”,确保将声学参数的数量减到最少。另一方面,“通过几何构造驱动声学模拟”,来专门处理直达路径 [25] 和早期反射,以便适当降低 CPU 成本。
下图展示了这两种范式的运用情形。
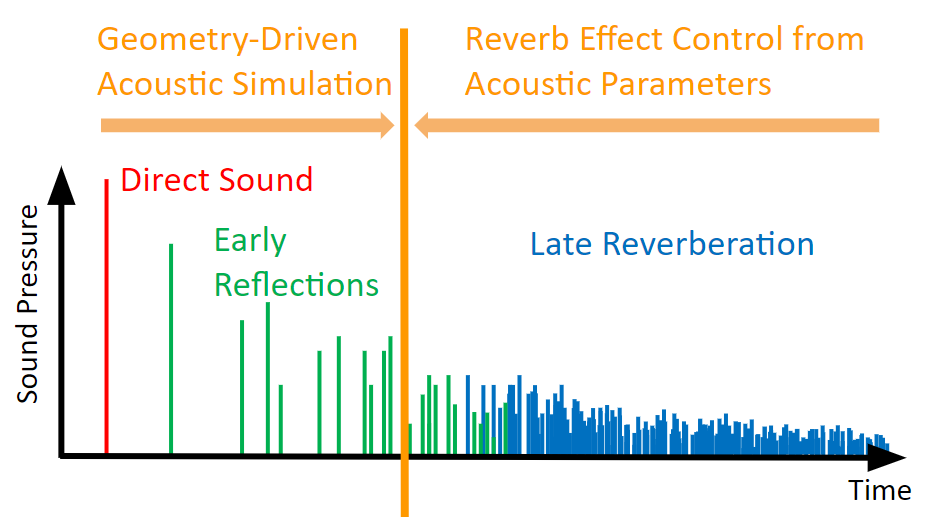
图 4 - 结合运用两种范式。Wwise Spatial Audio 分别针对 CPU 成本较低的早期反射和只需对空间进行粗略采样的后期混响运用不同的范式。
混响旋转
如前所述,每个 Room 只有一组对应的声学参数。也就是说,Room 在将相关信息告知混响效果器时并不会把发声体和听者的位置考虑在内。不过,Room 同时定义有朝向。换句话说,其可使用相对于听者的朝向。借助强大的 3D 总线,很容易就能做到这一点。
让我来解释一下。混响效果器会在 Auxiliary Bus 中输出一个多声道信号。该 Auxiliary Bus 与 Room 游戏对象绑定,同时采用由游戏定义的朝向。在听者处于 Room 内时,可将 Auxiliary Bus 信号用作音频源,并将 Spread 设为接近于 100%。在将 3D Spatialization 设为 Position + Orientation 时,声场会依据听者相对于 Room 的朝向进行旋转 [26]。最终,混响效果器发出的环绕声听起来就像跟周围世界而非听者绑定一样。
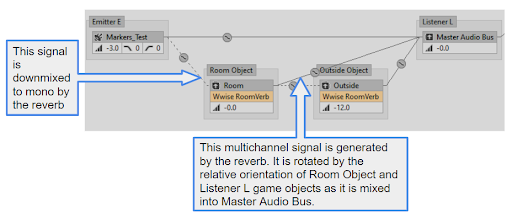
图 5 - Wwise Profiler 中的 Voice Graph 显示了 3D 总线,以及会在哪里依据 Room 和 Listener 游戏对象的相对朝向对多声道混响效果器输出信号进行旋转。注意,所有发送到 RoomVerb 的 Emitter 信号都会被所述混响效果器下混为单声道。也就是说,其会因而失去自身的方向性 [27]。
但是,为什么要旋转混响效果器输出的声场呢?大多数混响单块效果器会生成一个各向同性的信号(意即来自各个方向的能量相同),所以即便旋转也不会听出任何差别。Wwise RoomVerb 的 LR 模块便是如此。不过,该混响效果器的 ER 模块生成的信号具有明显的方向性,即便其并非源自游戏的几何构造也是如此。另外,研究表明现实生活中的混响有可能是各向异性的。比如,在处于走廊或隧道中的时候 [28]。所以,如果在 Spatial Audio Room 总线上的 Convolution Reverb 内使用了在真实隧道中录制的多声道 IR,那么游戏中隧道的朝向应当遵循原始的方向。听起来可能不太明显,但事实上其朝向跟画面是保持一致的,而且是动态变化的。这样可以让沉浸感得到显著提升。试试看能不能听出来。
音频 2 - OpenAir 官网上发布的 Innocent Railway Tunnel 的一阶 Ambisonics IR 录音的两个双耳渲染音效 [29]。两者都用 Wwise Convolution Reverb 和 Google Resonance 双耳插件进行了渲染,但其中一个经过了旋转。能分辨出其中差别吗?能猜出隧道的朝向吗?
未来展望/日后工作
模糊早期反射和后期混响之间的界线
根据我们的经验,每个音频团队都会采用不同的方式来在游戏中整合空间音频,并运用不同的音频功能、工作流程、美学设计和游戏系统,来设法以独特的方式开发游戏并力争将其打造得与众不同。我们希望各位能利用 Wwise Spatial Audio 来实现这一点。今后,我们会朝着以下两个方向继续努力:
A. 通过几何构造驱动声学模拟:能够通过几何构造和材料特性来模拟整个 IR。
B. 利用声学参数控制混响效果器:将更多有关游戏几何构造的信息告知混响效果器。
希望各位能依据游戏系统和美学设计以及团队流程和偏好来灵活运用这两种范式。
A. 通过几何构造驱动声学模拟
要想模拟整个 IR,首先要进一步提升射线投射引擎的性能。为此,我们已在着力开发一项功能,并有望在下一 Wwise 版本中发布。届时,诸位将可控制几何构造引擎的性能以使其满足自身预算需求。
B. 利用声学参数控制混响效果器
目前所用方法的缺点在于 Room 和 Portal 跟几何构造不同,其需要手动进行构建。
1. 几何构造预处理:我们目前正在设法减少 Unreal Engine Integration 中存在的问题:我们将会添加 Room 和 Portal 组件和对 Blueprint 的支持。在我们最近的直播活动中,各位可能已经瞧见了一些正在开发的便捷工具。它们可以将几何构造简化为 Room 和 Portal [30]。
2. 另外,我们还在努力为将 Room 映射到混响效果器提供合理的预估。其目的在于从 Room 形状提取上层混响要素,以便各位尽快投入到工作中并根据需要调节 Room。
而且,我们还将进一步提供更多工具,以便通过 RTPC 将几何构造信息告知混响效果器。敬请期待!
简单化和通用化
我在本系列博文的开篇引用了西蒙·阿什比 (Simon Ashby) 的话:“[设计师]只是事先设定混音规则,具体如何执行由系统决定。”也就是说,您可以灵活地运用各种工具和曲线来重新诠释各种物理量(如距离、衍射角度)以便根据需要对音频信号进行处理。前面,我们也探讨了实现这一点是多么重要。但之后只能期望在任何情况下都能一切顺利。不是吗?那么,我们如何帮助确保这一点呢?下面列出了几种可能的途径:
- 通过提供工具来解决问题以加强控制;
- 改进底层声学模型以使其更具通用性;
- 简化控件以便变通,哪怕不那么灵活。
这些途径的方向是截然相反的。毫无疑问,我们需要各位积极地参与交流,确保朝着正确的方向推进开发。

评论