
简介
在本文中,我会试着阐释团队在对《Scars Above》游戏的音频实施性能分析和优化时采取的各种措施。来让声音设计师同行了解我们所经历的过程,并提供有关如何规划和实施音频优化的建议。
这篇文章并不是专门为资深同行撰写的。不过要想深入领会本文所说的内容,还得对 Wwise 和 Unreal Engine 及其工作流程有一些基本的了解。在此,我假定各位拥有将声音导入、组织和集成到 Wwise 设计工具和 Unreal Editor 中的经验。
《Scars Above》采用我们的自研引擎基于 Unreal Engine 4.27.2 和 Wwise Unreal Engine Integration 2021.1.9.7847.2311 编译。
目录
优化的一般原则
在制作游戏的过程中,优化是很重要的一环。在大多数情况下,优化发生在制作的后期。不过,建议在制作的前期阶段就制定优化计划,因为要谨慎地确定音频预算并了解游戏的限制。通过将预算控制在预定的限制范围内,可确保游戏在各种平台和配置下都能正常运行。在音频正常工作时,不会出现声音问题。一旦超出预算,就有可能出现各种问题。比如,声音卡顿、毛刺噪声和帧率降低。这会对游戏造成负面影响。如此一来,通过对音频实施规划和优化来设法使游戏保持最佳性能就变得非常关键。
就音频而言,我们可以采用很多方法来让游戏运行得更加流畅。有的靠降低音频素材的内存消耗,有的则侧重减轻音频线程的负荷。不过,其中的大多做法都有助降低内存和 CPU 用量。
因为使用了 Wwise 和 Unreal Engine,所以两端都要做相应的分析和优化。我会在下文中介绍我们在优化《Scars Above》的音频时采取的各种措施。
我们游戏存在的限制
在制作的后期,我们开始注意音频对游戏性能的影响。在跟编程团队讨论之后,我们就如何为每种平台编制音频预算达成了一致。
总的来说,我们的主要担忧是在 Gen 8 平台上出现内存不足 (OOM) 问题。因为 Gen 8 的内存资源存在一定的限制,尤其是在裸机版的 PlayStation 4 和 Xbox One 上(Gen 8 平台的可用内存约为 Gen 9 平台的一半)。我们一致认为,Gen 8 和低配 PC 的总计音频内存预算不应超过 250 MB。
除此之外,音频还会给 CPU 带来处理上的压力。这是因为每一帧都要执行很多计算。而且,我们要为整个游戏使用复杂的 Spatial Audio 设置,这些计算会产生很高的成本,尤其是在 Gen 8 平台上。因为在 Wwise Profiler 中可以轻松分析音频线程消耗,所以 CPU 的预算编制最终交给了音频团队自己决定。最终,我们决定将音频线程的总计 CPU 峰值的限值设为 100%,将 Gen 8 上的平均 CPU 用量定在 50% 以下,并将 Gen 9 和 PC 的平均 CPU 用量定在 30% 以下。
预算概要
|
总计媒体内存 |
总计 CPU 峰值 |
平均 CPU 用量 |
|
|
Gen 8 |
250 MB |
100% |
50% |
|
Gen 9 |
250 MB |
80% |
30% |
|
PC |
250 MB |
80% |
30% |
表 1 - 各种平台上的音频在内存和 CPU 预算方面的限制
音频在内存或 CPU 方面的问题
在游戏当中,音频问题有很多种表现形式。在这里,我将介绍其中最常见的四种:内存不足 (OOM)、CPU 峰值、Voice Starvation 和 Source Starvation。
内存不足 (OOM)
在无法为新的进程分配更多内存时,系统会出现内存不足 (OOM) 问题。在超出平台上可用的最大物理内存或声音引擎的最大分配内存(在 AkMemSettings::uMemAllocationSizeLimit 初始化参数中定义)时,就会发生这种情况。在超出物理内存、声音引擎初始化失败、SoundBank 加载失败、跳过过渡或超出声音引擎内存时,OOM 问题可能会导致系统发生崩溃。
诸多原因都可能导致发生 OOM 错误。管理得当的话,音频一般只会占总计内存消耗的一小部分。不过,在为游戏编制预算时,一定要确保不超出商定的声音引擎内存限值。
CPU 峰值
音频线程负责完成对音频的大部分处理。它跟游戏线程是分开的,并会被 Wwise 音频引擎持续占用。Wwise Profiler 中的所有 CPU 测算都跟音频线程的消耗有关。
在音频线程无法在一帧之内渲染所有声音时,Wwise Profiler 中显示的消耗量会超过 100%。出现这种情况的原因有很多,主要是由于该帧的音频计算要求对音频线程来说负荷太重了。在《Scars Above》中,导致出现 CPU 峰值的主要原因是 Spatial Audio 路径传播计算以及同时注册和注销大量发声体。
对于孤立出现的 CPU 峰值,如果数值不是太高,不一定会导致音频问题。所以,我们可以放心地将总计 CPU 峰值的限值设为 100%(表 1)。但是,如果 CPU 峰值过高(以百甚至千为单位)或出现大量连续峰值,音频引擎可能会出现毛刺噪声或声音卡顿问题。
Voice Starvation
在音频线程无法连续多帧渲染一帧之内的所有声音时,会出现 Voice Starvation 错误,进而导致总计 CPU 消耗达到 100%。这些错误会以声音卡顿和毛刺噪声的形式表现出来。在开发过程中,我们在 Gen 8 主机尤其是基础 PS4 平台上遇到了 Voice Starvation 错误。因为有些游戏区域存在大量复杂的 Spatial Audio 几何构造,并且很多发声体在每一帧都需要执行相应的计算。事实证明,降低 Spatial Audio 的复杂程度并限制同时加载的发声体数对解决 Voice Starvation 错误有很大帮助。
Source Starvation
Source Starvation 错误跟内存而非 CPU 有关。在直接从磁盘流播放的声音无法及时向 Streaming Manager 提供数据时,就会发生这种错误。出现这种情况的原因有很多,通常是同时播放的流播放文件太多,或者磁盘(I/O 设备)速度太慢而无法同时处理所有数据。这种情况同样会以声音卡顿的形式表现出来(尤其对于流播放的声音)。虽然调整某些 I/O 设置有助减少 Source Starvation 错误的发生,但最有效的解决办法是限制同时从磁盘流播放的声音数量(本文稍后会讨论有关流播放声音的更多细节)。
性能分析
性能分析是优化过程中必不可少的一步。在开始优化游戏时,必须评估内存和 CPU 消耗的当前状态,并找出可能影响这些参数的潜在瓶颈。
需要注意的是,所有测试都要在 Testing 或 Shipping 版本中做,而不能在 Unreal Editor 或 Development 版本中做。虽然通过在 Unreal Editor 中测试能对游戏的行为有一个大致的了解,但在适当的版本中测试可确保获取准确的性能数据并以此优化音频。
Wwise Profiler
Wwise Profiler 是我们用来评估音频性能的主要工具。虽然乍看之下并不是很直观,但是它可以提供大量的数据,清楚地呈现音频的当前状态,便于查明游戏当中可能出现的各种性能问题。
在实施性能分析的过程中,我们会重点关注几项 CPU 和 Memory 参数。这些参数会显示在 Wwise 设计工具中 Profiler 布局下的 Performance Monitor 分区。
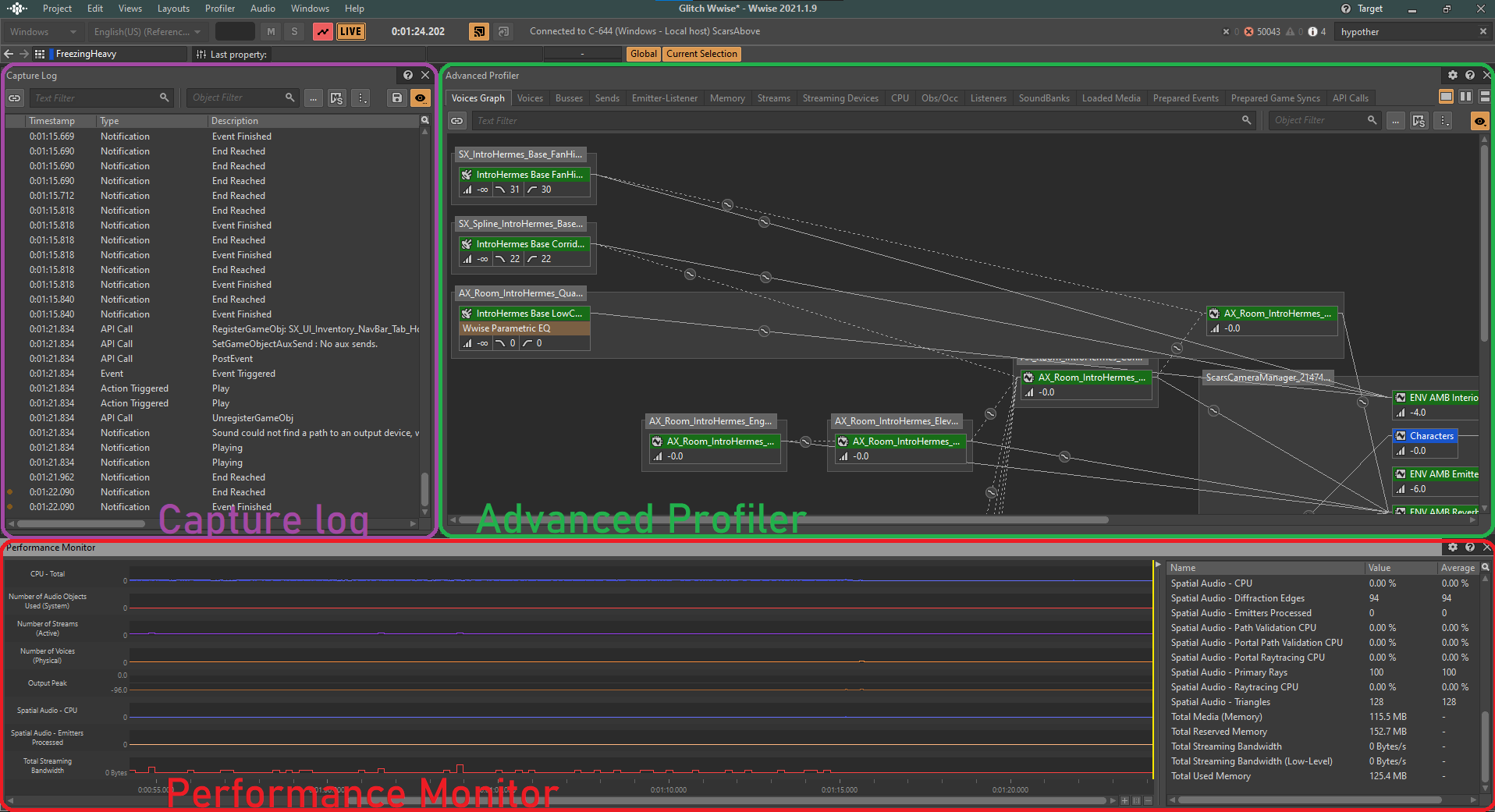
图 1 - Wwise 的 Profiler 布局
在 Performance Monitor 中,可直观地察看游戏中各种声音性能参数的实时状态和数值。
通过监控这些重要参数,可清楚地了解游戏在任意给定时刻的声音性能。Profiler 会详细记录每一帧游戏中发生的各种操作。要对特定的帧进行分析,可沿着监控器拖动黄色光标来检查各个时间点:
图 2 - Performance Monitor 时间线
比如,如果观察到 CPU 消耗激增或坐标图上的声部数突然增加,可将光标移到这一时刻来察看该帧触发的各种操作及总计 CPU 消耗。
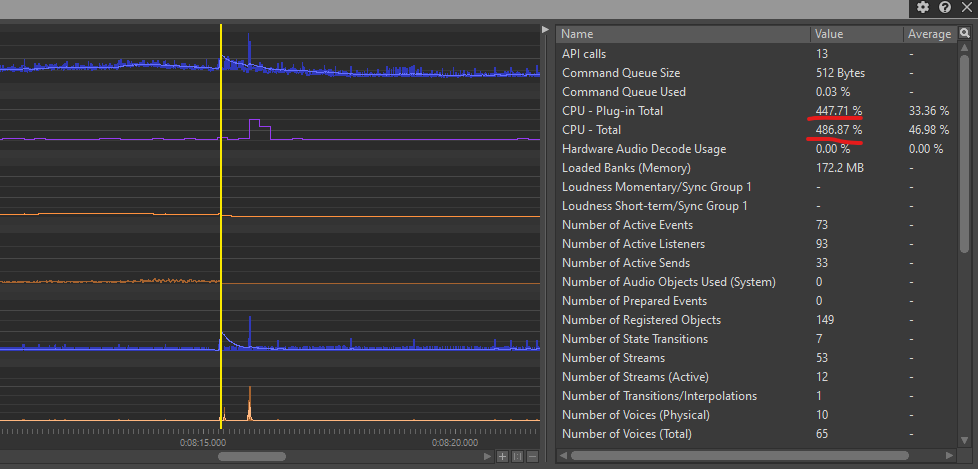
图 3 - CPU 峰值示例
Wwise Profiler 参数
以下参数是我们通常用来监控和衡量游戏声音性能的关键指标:
- CPU - Total:追踪与音频处理相关的总体 CPU 用量;
- CPU - Plug-in Total:测算游戏中所用音频插件对 CPU 的具体消耗;
- Number of Voices (Physical):指示同时播放的活跃声部总数;
- Number of Streams (Active):指示活跃的音频流数;
- Spatial Audio - CPU:追踪与 Spatial Audio 处理直接相关的 CPU 用量;
- Spatial Audio - Emitters Processed:显示为 Spatial Audio 计算处理的发声体数;
- Total Reserved Memory:反映为音频素材预留的内存量;
- Total Media (Memory):测算媒体素材的总计内存消耗。
以上所述的大部分参数都是用来监控 CPU 消耗的,只有 Total Media (Memory) 和 Total Reserved Memory 用于追踪内存消耗。
在 Unreal Editor 中实施性能分析
遗憾的是,Wwise 音频数据在 Unreal Editor 中的呈现并不清晰。Wwise 不会将内存或 CPU 消耗数据回传给 Unreal Engine。这限制了我们在这方面的性能分析能力。虽然 Unreal Insights 或 Low-Level Memory Tracker 等工具有助于从 Unreal Editor 端对 CPU 或内存实施性能分析,但是它们并没有提供与 Wwise 素材和进程直接相关的信息。
我们当前能做的就是利用 Output Log 来识别因声音实现不当而导致的错误。为此,可将与 Wwise Profiler 相关的日志消息跟 Unreal Editor 中的 Output Log 相互对照。Output Log 中显示的 Wwise 错误一般会添加 LogAkAudio 前缀。这样方便通过筛选更快地搜索问题。在提交问题报告时,QA 团队可轻松附上包含这些错误的日志文件以便做进一步的调查。
向 QA 部门寻求帮助
当然,报告问题最有效的方法是让 QA 团队使用 Wwise Profiler 来测试游戏并在错误报告中附上相应的 .prof 文件。不过,这种方法要求 QA 团队掌握有关如何运行 Wwise Profiler 的知识。不得不说,有 QA 同事专门负责测试声音性能确实给我们带来了很大的帮助。所以,也建议各位与管理层商讨是否可将声音性能分析纳入到 QA 的职责范围。
优化
在本章节,我们将探讨用于提升素材性能的各种优化技术。其中包括调整不同的声音设置、更改素材在游戏中的播放方式,以及在必要时通过加载和卸载素材高效地加以组织以节省资源。
对素材本身加以处理
就素材来源(所创建的声音)来说,我们可以运用各种技术来实施优化。比如,根据不同的情况修改这些声音的各项属性,以确保在保持保真度的同时减少资源消耗。这样可以在不影响素材品质的前提下减少其对资源的消耗。
设为从磁盘流播放
为了减少音频对内存的消耗,可将文件设为从磁盘流播放。这样不仅有效,而且非常简单。这种方法最适合对时机要求不高的长文件(即声音不一定要与画面完全同步)。比如,循环环境声、音乐或对白。注意不要将与画面紧密相关的一次性声音(如枪声、撞击声或脚步声)设为从磁盘流播放,因为从磁盘而非内存加载这些声音需要花更长的时间,并且流播放可能会给声音带来延迟。
在设为从磁盘流播放时,所有流播放文件的媒体都不会纳入到 SoundBank 中。Wwise 的 Stream Manager 会直接从磁盘打开和读取这些文件。根据平台的流播放带宽,我们可以同时播放很多流播放声音,从而大大减轻内存负荷。
事实上,为声音启用流播放选项非常简单。只需在声音或其父对象的 General Settings 选项卡中选中 Stream 方框即可。
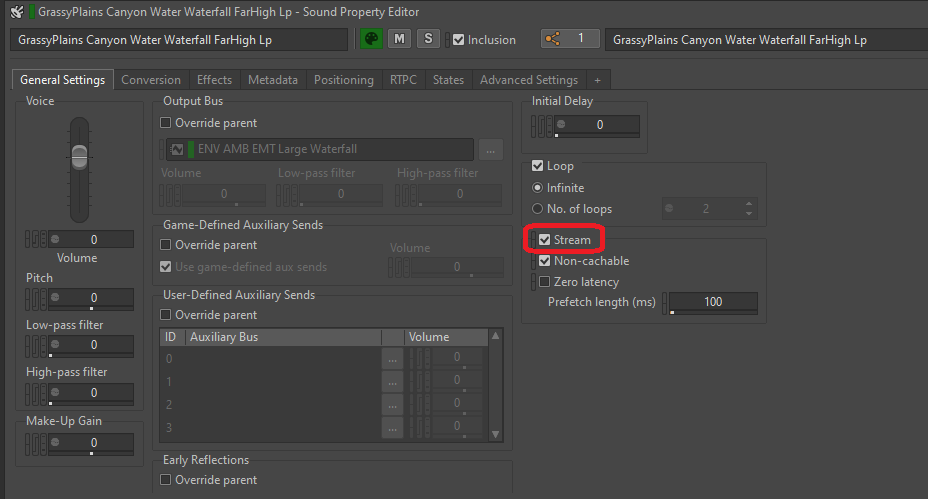
图 4 - 针对 SFX 对象启用 Stream 选项
要让流播放声音与画面更加同步,我们可以选中 Zero latency 复选框。这样会把文件的一小部分从头加载到内存中,使其可以在流播放其余部分时无延迟地播放。预加载部分的长度由 Prefetch length 时间决定。
- Source Starvation 错误
如上所述,在流播放带宽达到极限而管理器无法再从磁盘读取数据时,就会发生 Source Starvation 错误。这可能会导致声音卡顿及其他各种问题。因此,在将声音设为 Stream 时要注意可能出现的问题。
缩短音频源的长度
说到长音频文件,我们不妨聊聊那些占用大量空间但在整个声音持续期间内容基本相同的音频文件。这些文件一般都是基底环境声(也叫 Bed)。比如,房间底噪和持续循环的风声。如果出于某种原因而无法将这些循环设为从磁盘流播放,可通过缩短它们的长度来大幅降低这些声音的内存用量,尤其是在所用转码设置优先考虑音质而不是文件大小时。
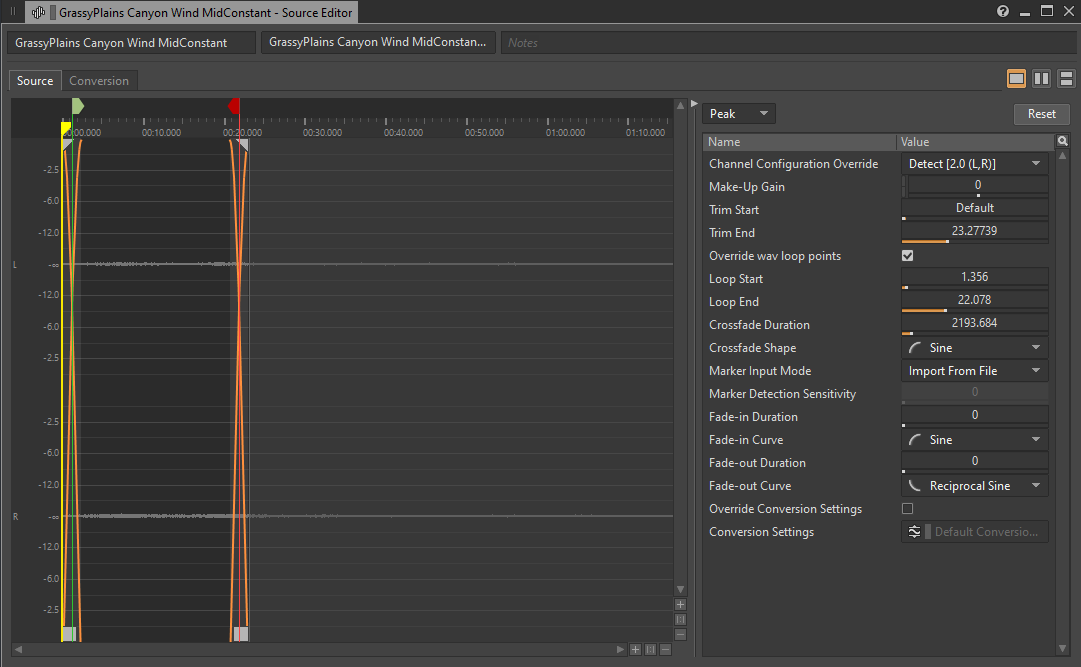
图 5 - 缩短基底环境声
还有一种方法可以缩短环境声,就是创建一系列短的声音片段,然后放到 Random Container 中。同时,将 Play Mode 设为 Continuous,并将 Loop 设为 Infinite。这样可以用更少的内存消耗实现内容的多样变化。注意,这可能会略微增加 CPU 负荷,因为片段之间的交叉淡变会生成比播放单个音频文件多一倍的声部。
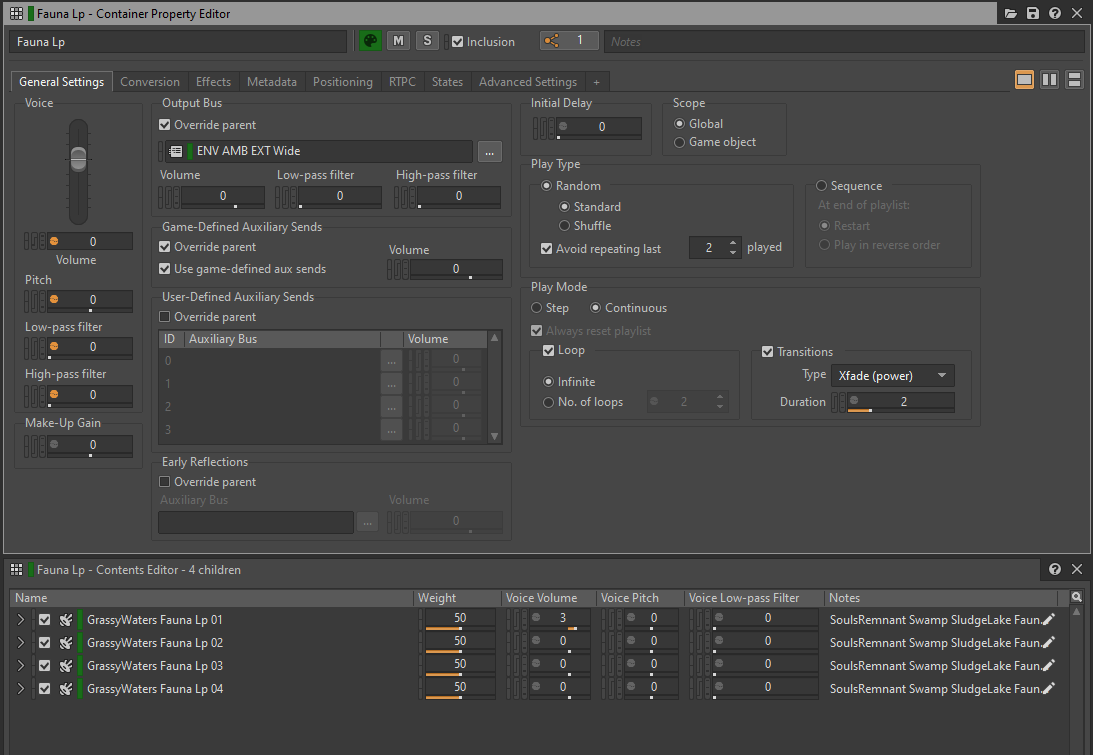
图 6 - 带交叉淡变过渡的循环 Random Container
设置 Conversion Settings
在向音频文件应用 Conversion Settings 时,要决定各种平台的最终文件格式和转码品质。文件格式取决于对原始 .wav 文件转码时所用的编解码器、声道数、采样率和编解码器的品质设置。
通过选择适当的 Conversion Settings,可进一步减轻游戏的内存和 CPU 负荷。发售版本中一般不需要使用无损文件格式,因为像 Vorbis 这样的压缩格式可以提供很高的压缩比率,同时又不会对品质产生明显的影响。注意,编码的文件在播放前需要进行解码,而有些实施解码的插件可能会更耗费 CPU。
大多数声音会使用相同的 Conversion Settings。为此,可使用 ShareSet 将 Conversion Settings 组织成不同的预设。
对此,我们在所有平台的 "Default Conversion Settings" ShareSet 预设中使用了 Vorbis(Quality 设为 4)并找到了很好的平衡点。虽然也可选用 WEM Opus 或 ATRAC9 等其他编解码器来在 Gen 8 平台上实施硬件解码,不过我们对 Vorbis 的性能已经很满意了,并不想花时间将其与 Gen 8 硬件集成(Audiokinetic 已针对所有平台对 Vorbis 的 Wwise 实现做了大幅优化)。不仅如此,Vorbis 还支持在 Gen 9 平台上实施硬件解码。这对我们来说就更加方便了。
"Default Conversion Settings" ShareSet 预设可在 Project Settings 的 Source Settings 选项卡中设置:
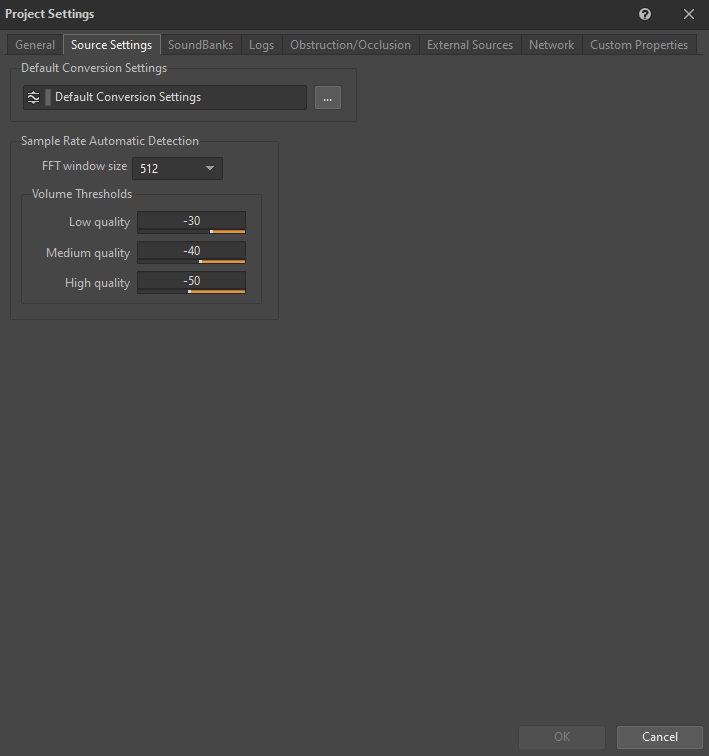
图 7 - Project Settings 窗口的 Source Settings 选项卡
下表对 Wwise 支持的编解码器做了各方面的对比。各位可根据其中的信息选用适合自己的编解码器。
|
文件格式 |
压缩比率 |
CPU |
内存 |
常见用例 |
限制 |
|
PCM |
1:1 |
极低 |
高 |
高保真声音。 |
无。 |
|
ADPCM |
4:1 |
低 |
中 |
环境声和音效。 |
仅在 64 个采样边界循环。 |
|
Vorbis |
3-40:1 |
中到高 |
中等到极低 |
对白、音乐、环境声和音效。 |
元数据开销比其他格式稍大;最好不要将其用于太短的声音(短于几十毫秒)。需要使用 Seek Table 进行寻址。 |
|
AAC |
3-23:1 |
高;低(在 iOS 中使用硬件辅助解码器时) |
中到低 |
背景(非互动)音乐。 |
元数据开销极大。设置时间较长。不适合精确到采样点的播放。 |
|
WEM Opus |
10-60:1 |
高(不启用硬件加速);极低(启用硬件加速) |
中等到极低 |
对白、简单音乐、环境声和音效。 |
功能限制因平台性能而异。 |
表 2 - 各种可用编解码器的对比(摘自 Audiokinetic 文档)。
- Sample Rate Automatic Detection
Sample Rate Automatic Detection 选项允许 Wwise 编码器对声音文件的内容实施分析并为其选择最适宜的采样率。比如,如果声音主要由低频内容构成,可选用较低的采样率来缩减文件大小,同时又不会对保真度产生明显的影响。不过对于《Scars Above》,我们决定不使用采样率自动检测功能。这款游戏中并没有太多以低频内容为主的声音。另外,我们希望确保所有声音的采样率都跟平台的原始采样率 (48 kHz) 一样。这样有助于防止在升采样到 48 kHz 时产生混叠杂音。另外我们还注意到,Vorbis 编码器在对使用 16 kHz 或更低采样率的声音实施转码时可能会导致音频品质不佳,因为编解码器针对更高的采样率做了专门的调整。
转码为单声道
为了减轻游戏的内存、磁盘和 CPU 负荷,还可使用 Conversion Setting ShareSet 预设将声音转码为单声道(如适用)并将声道配置设为 Mono。
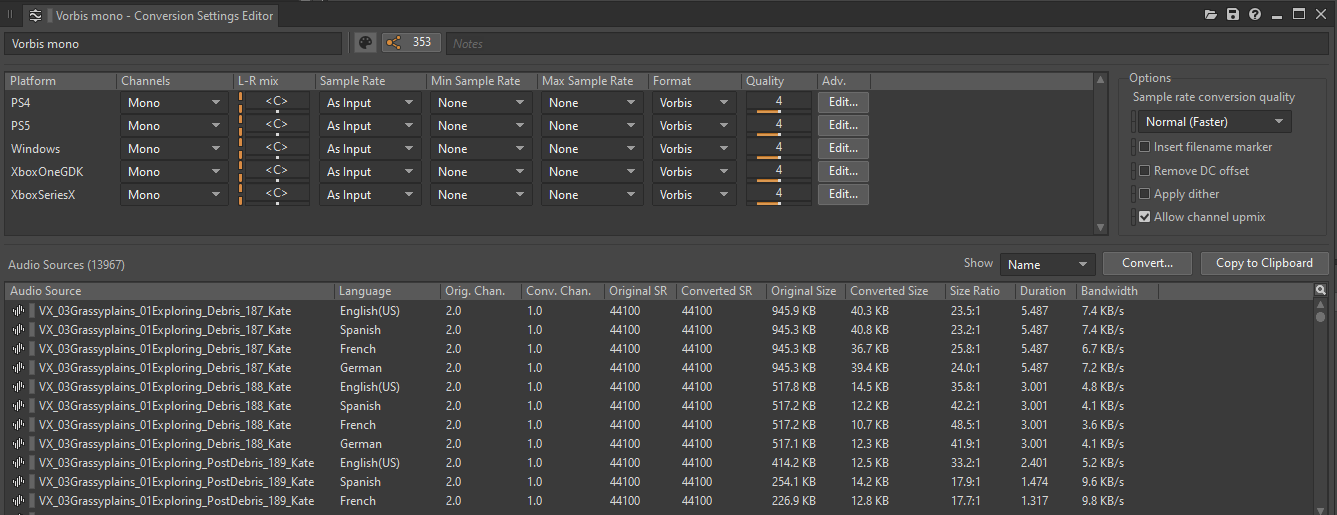
图 8 - Conversion Settings ShareSet 预设编辑器
跟单声道文件相比,多声道文件的内存占用要大很多。比如,双声道立体声文件占用的空间是单声道文件的两倍。
更重要的是,我们要考虑多声道文件作为音频源在游戏中的行为。要知道,音频的每个声道对应游戏中的一个声部 (Voice)。这一规则同样适用于音频对象 (Audio Object)。也就是说,每个声道相当于一个音频对象。在为多声道声音插入插件时,每个声道会创建一个插件实例。除非被覆盖,否则层级结构中的所有子对象会适用同样的规则。
由此可见,使用多个声道的音频文件会增加成本。声部/音频对象的增多意味着要分配额外的 CPU 资源用于这些声音的插件、转码和混音。
为此,可考虑将符合以下若干条件的声音转码为单声道:
- 所有声道的内容都一样或者很相似;
- 声音使用衰减半径很小的衰减预设;
- 声音使用 Spread 值极低的衰减预设。
适合转码为单声道的声音包括:VO、关卡中的小发声体(如小股敌人和小群动物)发出的声音、部分 UI 音效、拟音(取决于其大小和距离)、关卡中的简单互动音效等。
要将文件转码为单声道,可转到声音或其父对象的 Conversion 选项卡,选中 Override parent 选项并选择适当的 ShareSet 预设来覆盖 Default Conversion Settings 预设。
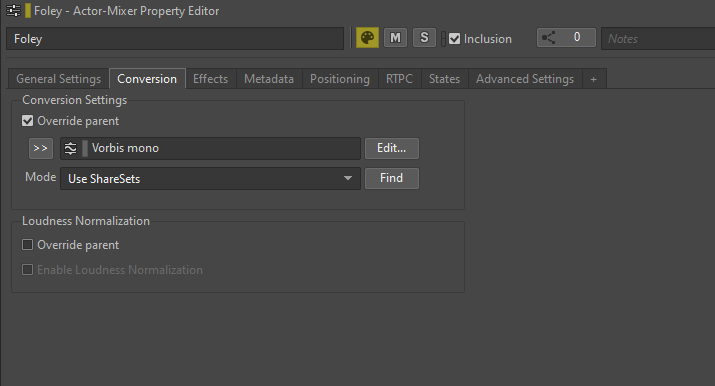
图 9 - 覆盖 Conversion Settings 预设
要简要了解所有配置为转码为单声道的对象,可查看 Conversion Settings ShareSet 预设的引用列表:
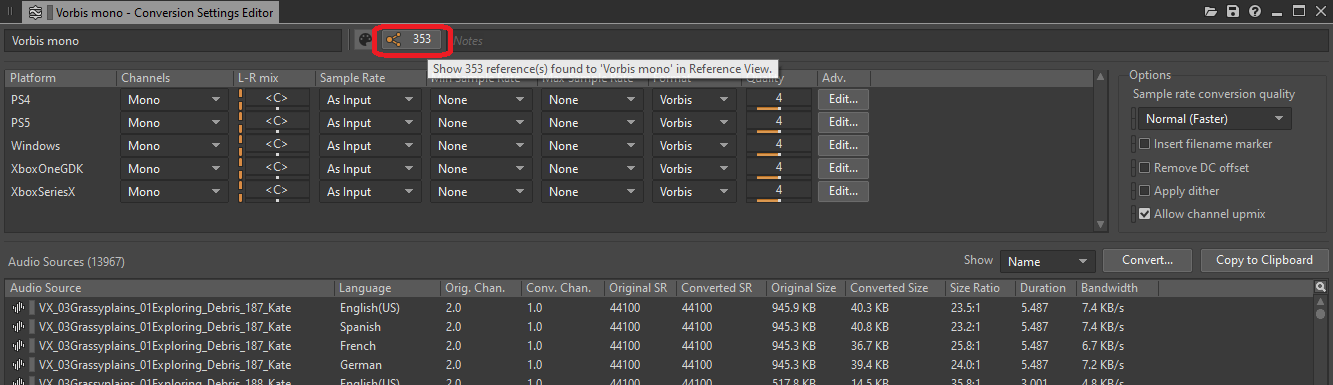
图 10 - Conversion Settings ShareSet 预设编辑器的 Reference 按钮
单击该按钮可打开 Reference View 窗口,其中列出了对该 ShareSet 预设的所有引用:
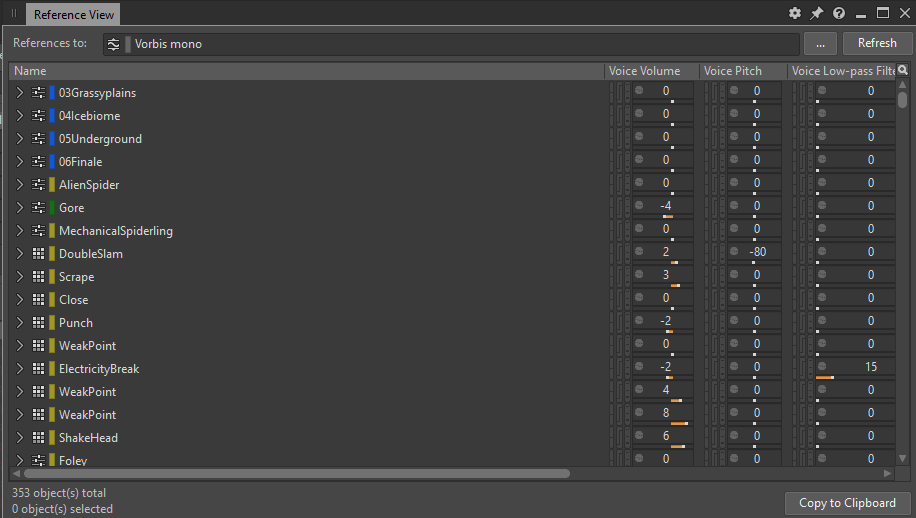
图 11 - Reference View 窗口显示对 Vorbis mono 预设的所有引用
粘合 Blend Container
我们在 Wwise 工程中还采用了一种优化做法,就是合并或者说粘合所有 Blend Container。我们采用“粘合”一词来表示将音频源(本例中为 Blend Container)的输出录制到新的音频文件中并用新文件替换音频源的过程。在此过程中,所有 Blend Container 都会被替换为单个 SFX 对象。
在游戏的制作阶段,我们导入了大量声音。借助 Blend Container,我们可以在单个容器中便捷地组织多个声音分层。这样就可通过在 Event 中触发单个 Play 操作来轻松测试容器。Wwise 中的分层让我们可以进一步完善这些分层的组合。通过将其全部置于同一父对象之下,可轻松地以不同方式触发和处理这些分层。
不过,只用 Blend Container 来组织分层就有点过了。Blend Container 的主要用途是创建 Blend Track。藉此,可在容器内的子对象之间定义精确的过渡,并使用不同的游戏参数控制这些过渡。
因为在触发每个 Blend Container 时都会同时播放多个子容器,所以我们必须留意与 Blend Container 相关的 CPU 负荷。比如,如果有个 "Gunshot" Blend Container,其中的 Impact、Tail、Foley 和 Mechanics 分层都有独立的子容器,那么触发 Blend Container 就会同时播放这四种声音。
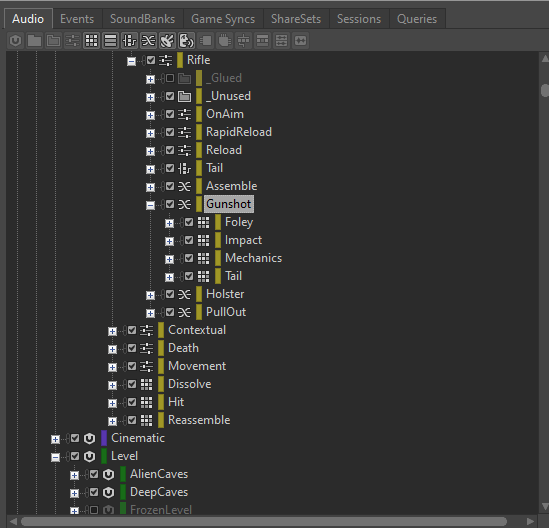
图 12 - 示例的 Blend Container 包含四个子容器
假设 "Gunshot" Event 中的每个分层都配置为双声道立体声播放,那么触发 "Gunshot" Event 将占用八个实声部。如果快速触发多个 "Gunshot" Event,声部数就会迅速增加。另外,如果在 Blend Container 上插入了插件,那么每次触发 "Gunshot" Event 都会为每个插入的插件生成八个实例。
通过粘合 Blend Container,可将声部数从八个减少到两个,从而大大减轻内存和 CPU 负荷。
如果 Blend Container 中的子容器是 Random Container,用于为每个 "Gunshot" Event 生成不同的混合分层,我们可以根据需要多次粘合同一 Blend Container,来在保持保真度的同时创造足够的变化,由此实现对 Gunshot 声音的优化。
就粘合 Blend Container 而言,最好的方法是对 Wwise 设计工具本身的输出进行录音。通过在 Master Audio Bus 上插入 Wwise Recorder 插件并进行适当配置,就可将 Blend Container 每次触发的声音录制到磁盘上的特定 .wav 文件。
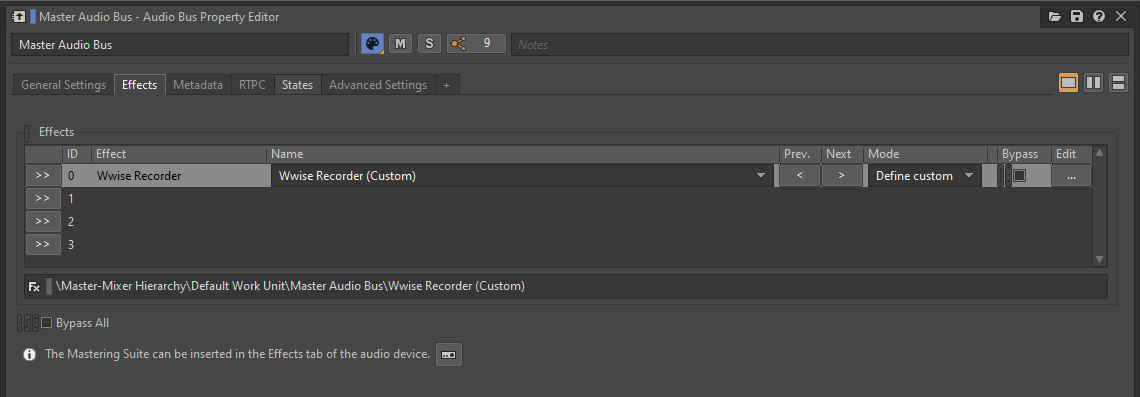
图 13 - 在 Master Audio Bus 上插入 Wwise Recorder 插件
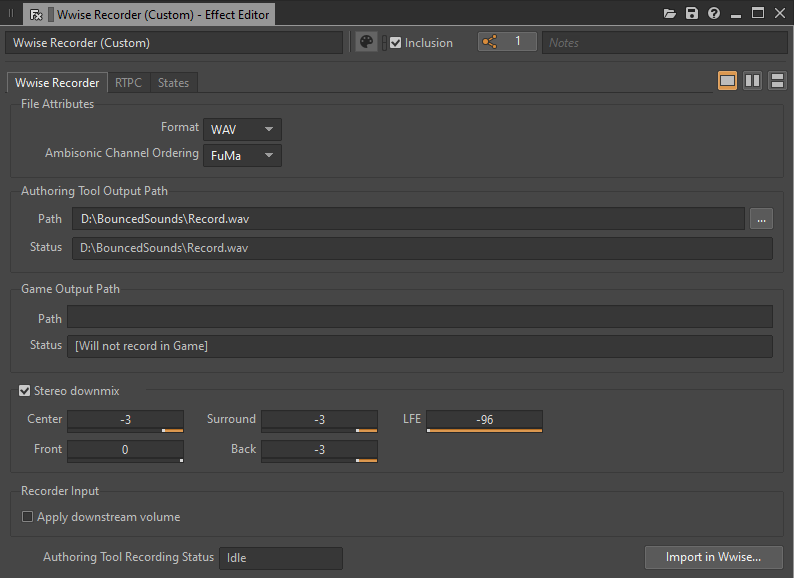
图 14 - Wwise Recorder - Effect Editor 窗口
在 Blend Container 完成播放后,会创建相应的 .wav 文件。注意,在继续录制新的片段前,要将录制的文件移到别的位置或为其指派一个合适的名称。这样可以避免每次播放时把之前的录音覆盖掉。
在生成足够数量的变化版本后,可将所有录制的文件导入到新建的 Random Container 中。然后,就可使用此 Blend Container 来替换 Event 中的 Blend Container。注意,在完成录制后不要忘了从 Master Audio Bus 上移除或旁通 Wwise Recorder 插件。
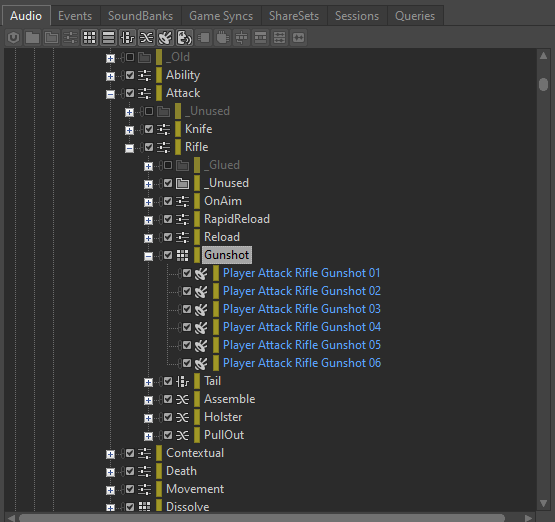
图 15 - Random Container 包含生成的 Wwise Recorder 变化版本
另外,最好将当下未使用的 Blend Container 保留在工程中。这样方便将来对混音进行修改并重复整个过程。个人建议将其放在 _Glued 文件夹中并排除在外。如果我们想生成新的变化版本,就可很容易地将其再包含进来,重新插入 Wwise Recorder 插件,然后做必要的更改并录制新的片段。
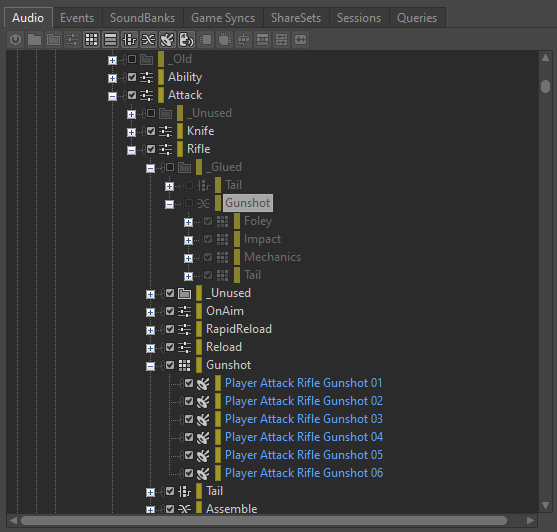
图 16 - 将 Blend Container 排除在外
优化效果器处理
在 Wwise 中使用所提供的插件效果器处理声音会占用大量 CPU 甚至内存资源。不过,有几种方法可以在 Wwise 环境中对处理加以优化并提升性能。在接下来的章节中,我会详细介绍这些优化方法。
- 渲染效果器
如前所述,在 Wwise 中向音频对象添加每个插件效果器时都会为对象及子对象的各个声道创建实例。这些插件所做的处理是在游戏当中实时计算的。不过,如果处理效果器不需要通过游戏参数实施动态修改,我们也可以选择对其进行渲染。
通过启用 Render 选项,可在打包到 SoundBank 中之前直接将效果器嵌入到声音中。这样可以节省运行时的处理资源。不过就像前面说的,完成渲染后将无法使用游戏参数 (RTPC) 修改或旁通效果器。
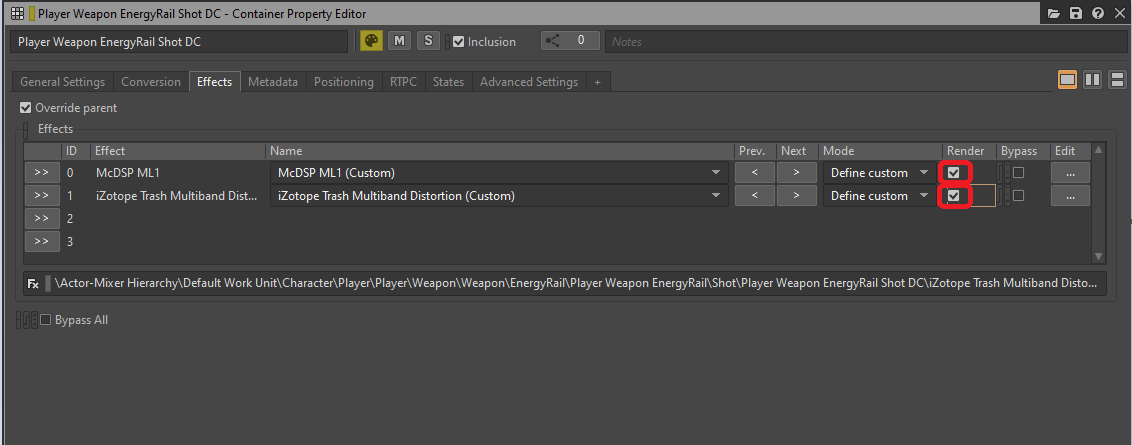
图 17 - 在 Container Property Editor 的 Effects 选项卡中选中 Render 选项
有一种简单的方法可以获取所有可渲染的插入效果器。只要生成一份 Integrity Report(相应窗口的默认快捷方式为 [Shift + G]),就会列出各个平台上所有可通过渲染进行优化的效果器实例并显示以下信息:
The effect could be rendered to save CPU, since no parameter will change in game.
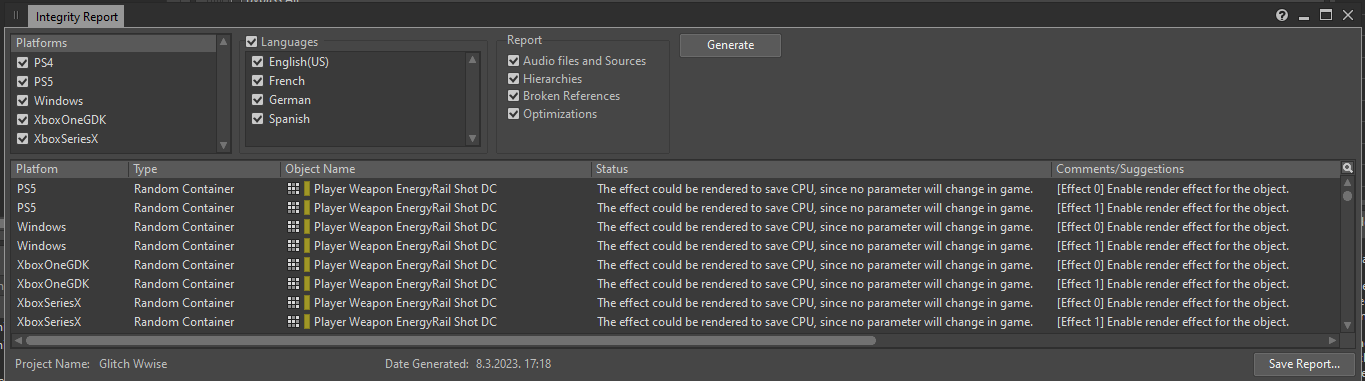
图 18 - Integrity Report 窗口
在此,可打开与包含效果器的对象对应的 Property Editor 并启用 Render 选项。在完成之后,这些效果器就不会再出现在 Integrity Report 中(因为这些与渲染相关的问题已经得到解决)。
- 在总线上插入效果器
一般来说,在使用无法渲染的效果器时最好将其插入到总线而非 Actor-Mixer Hierarchy 或 Interactive Music Hierarchy 中的对象上。这是因为总线的声道数是固定的,对总线上所插入效果器的实例化次数跟总线上的声道数相同。相较之下,如果在 Actor-Mixer 对象上插入效果器,就会为其每个子对象的各个声道生成效果器实例。两种方法的最终效果应该是一样的,但前者产生的效果器实例更少一些。
不过,在总线的声道数多于发送到该总线的对象数时,这条规则也有例外。在这种情况下,总线会创建比 SFX 对象更多的效果器实例。对此,最好在 SFX 对象上插入效果器。这条规则同样也有例外。比如对于混响效果器,每个声道的性能成本可以忽略不计。一般来说,最好将这种效果器用在 Auxiliary Bus 上。
- 将 General Settings 中的处理参数替换为效果器
要进一步节省资源,可将总线或对象的某些参数视为在运行时消耗处理资源的效果器。在游戏当中,General Settings 选项卡中的 Bus Volume、Voice Volume、Pitch、Low-pass filter 或 High-pass filter 等参数仍会占用 CPU 资源。如果游戏参数没有对其进行修改,可将其替换为专门的效果器插件,然后进行渲染。
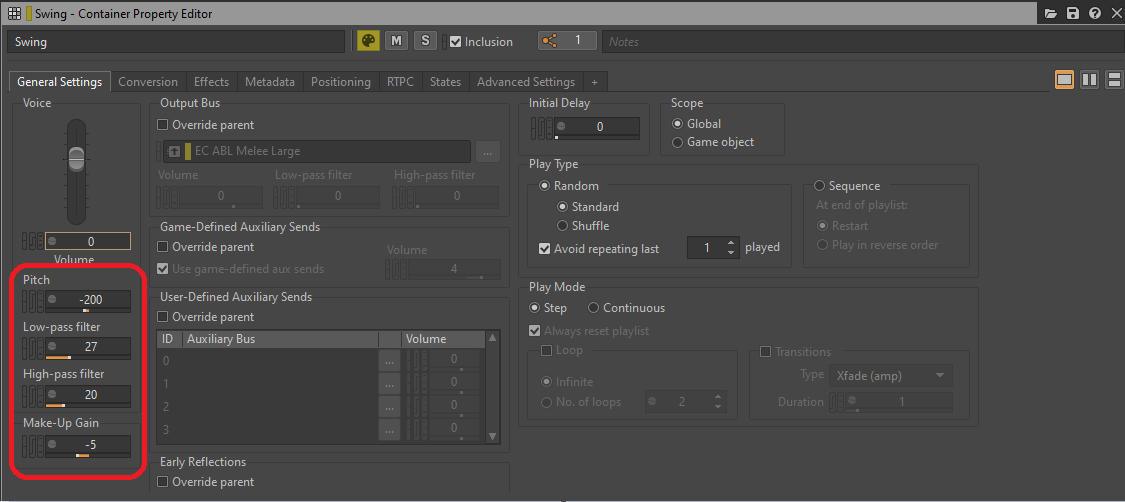
图 19 - General Settings 选项卡中的各项处理参数
Low-pass filter 和 High-pass filter 可替换为 Wwise Parametric EQ 实例,Pitch 则可替换为 Wwise Pitch Shifter 或 Wwise Time Stretch 插件实例。Volume 或 Make-Up Gain 可替换为 Wwise Gain 插件效果器。
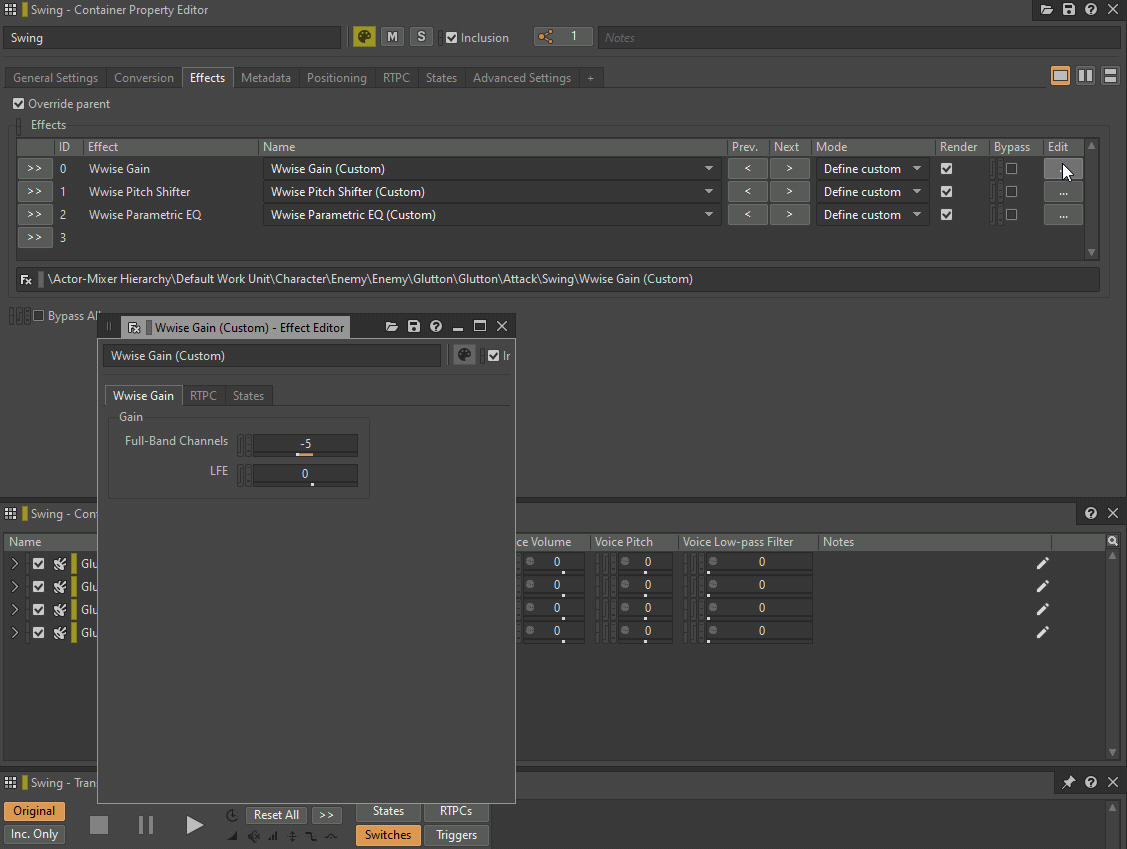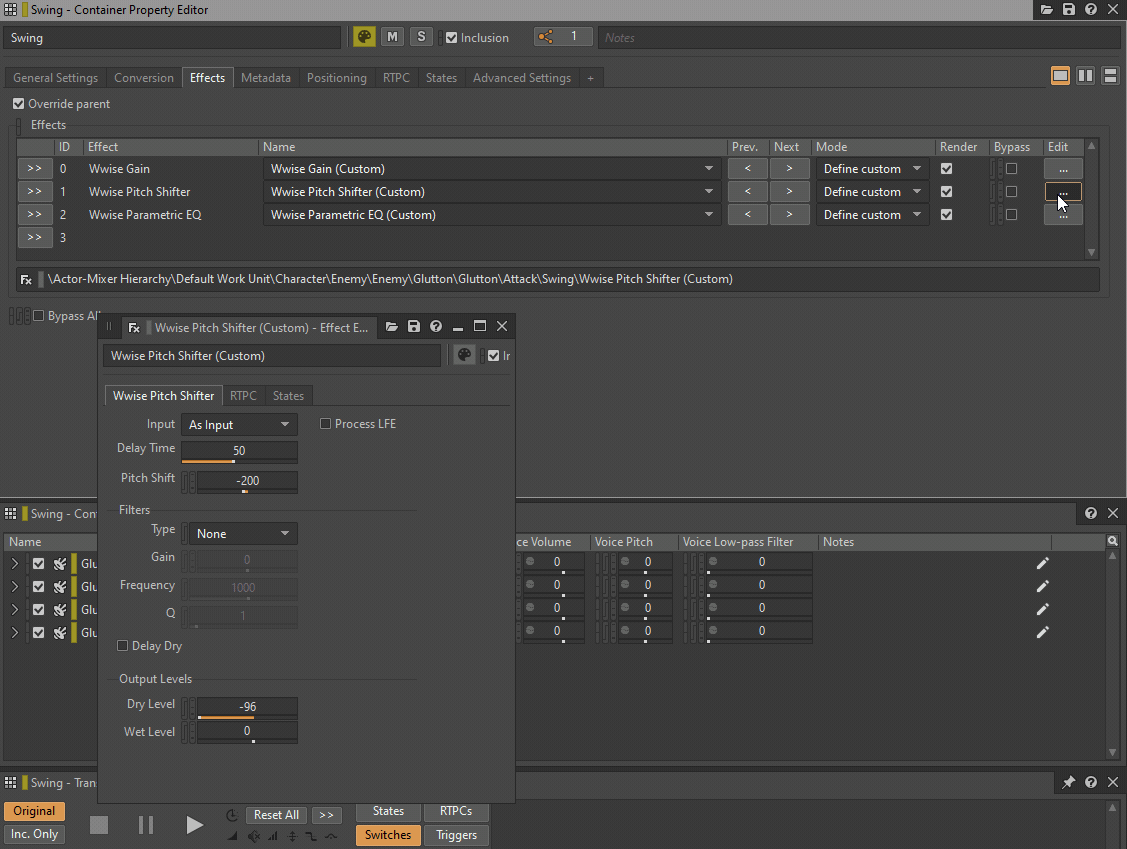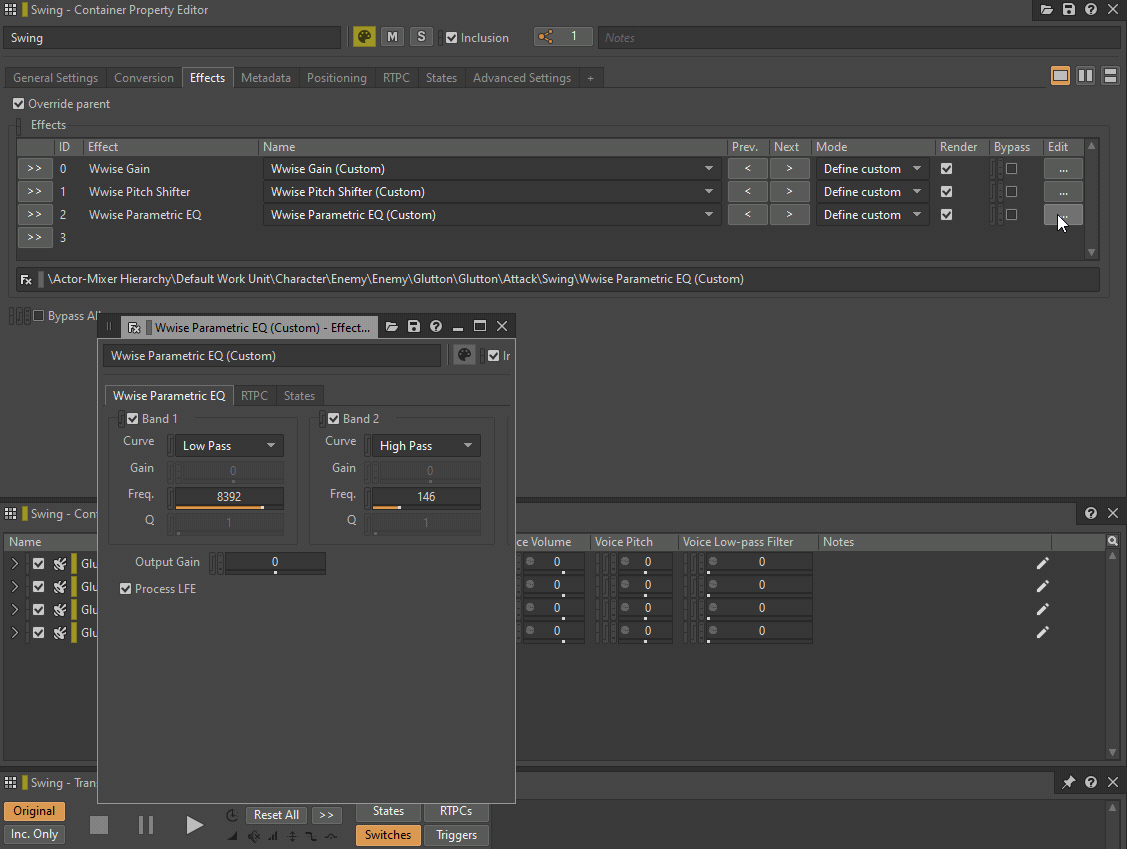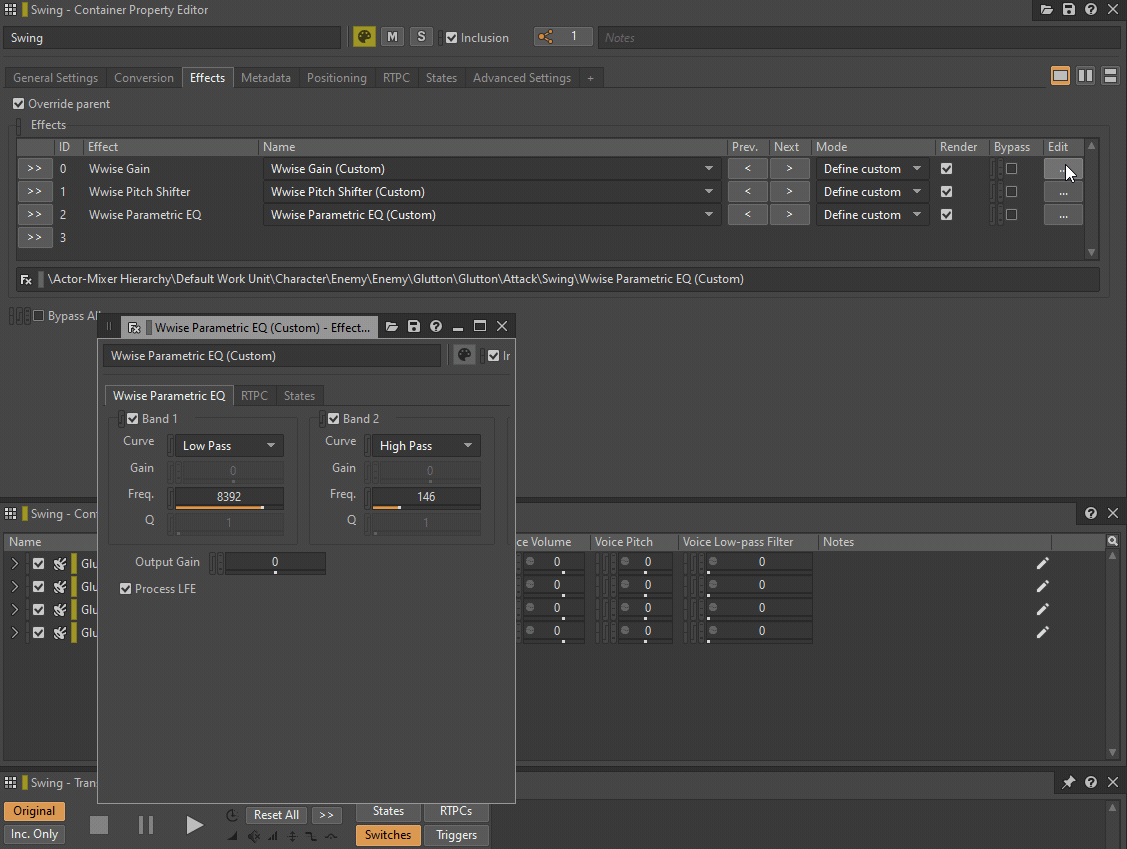
GIF 1 - 插入 Wwise 插件来替代 General Settings 参数
下面是 Audiokinetic 文档中的表格链接,其中列出了 LPF 和 HPF 值与 Cutoff Frequency 的对应关系:
Wwise 中 LPF 和 HPF 值与 Cutoff Frequency 的对应关系
优化素材的播放方式
在本节中,我将阐释如何播放和停止声音素材、声部和 AkComponent 的概念,以及可以采取哪些步骤来优化声音的播放和触发。
声部
游戏中播放的每个独立声音都会占用一个声部。在触发 Event 时,与之相关的音频源会在运行时成为声部。这些声部需要计算才能存在并适用各种行为。这些计算主要取决于要对所述声部做多大力度的处理。通过尽量减少计算,并只在必要时运行,可节省大量 CPU 资源。
要查看游戏中当前播放的所有声部,可在 Wwise Profiler 中连接到游戏,然后转到 Voices 选项卡:
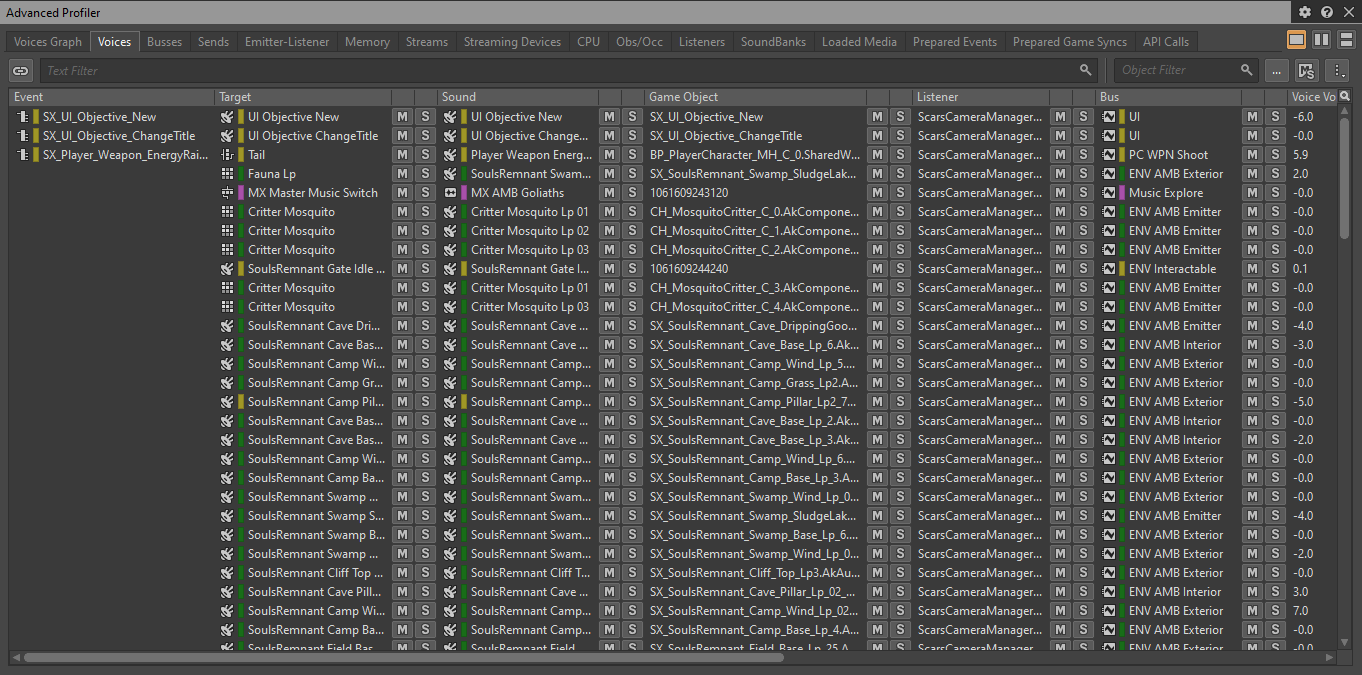
图 20 - Advanced Profiler 的 Voices 选项卡
- 虚声部
在声部活跃并发出声音时,我们将之称为实声部 (Physical Voice)。每个实声部在每一帧都要执行以下计算:
- 对音频文件进行解码;
- 对声音进行重新采样(使用时将应用 Pitch Shift);
- 效果器和滤波器处理;
- 音量计算。
在实声部无法被听到的情况下(比如关联 Actor 离得太远),可将其转为虚声部 (Virtual Voice)。虚声部会跳过音量计算以外的所有计算(音量计算旨在确定声音再次可被听到时的播放音量)。通过将实声部转为虚声部,可节省大量 CPU 资源。因此,确保没有听不到的声音保持活跃状态是优化游戏的重要一步。
各位可在 Property Editor 的 Advanced Settings 选项卡中为每个声音素材定义虚声部行为:
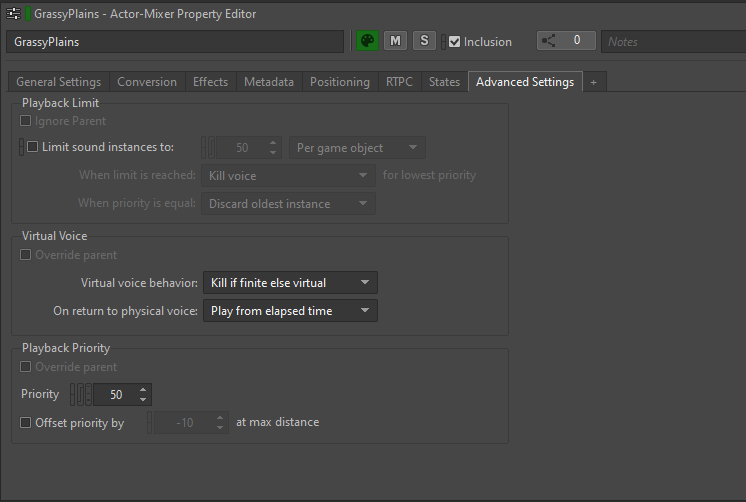
图 21 - Property Editor 的 Advanced Settings 选项卡
Virtual voice behavior 属性决定在音量低于 Volume Threshold 时会对声部做怎样的处理。
其中设有以下选项:
- Continue to play:声部保持活跃状态,继续正常播放;
- Kill voice:声部完全停止,不再播放;
- Send to virtual voice:声部转为虚声部,跳过音量计算以外的大部分计算;
- Kill if finite else virtual:若声音不是无限循环的,则在发送到虚声部时完全停止。若声音是无限循环的,则将其转为虚声部。
对于大多数素材,我们一般倾向于将默认值设为 Kill if finite else virtual。这几乎可以涵盖音量低于某个阈值时要对声音做的所有处理。非无限循环的声音将被终止,因为走远的话会听不到声音。无限循环的声音将被发送到虚声部。
在恢复为实声部状态时,我们选择了将所有虚声部设为 Play from elapsed time。这意味着除音量计算外 Wwise 还会追踪处于虚声部状态的时间。在声部再次变为活跃状态时,会继续播放,如同从未停止播放一样,从而保证玩家对游戏时间流的无缝感知。
- Volume Threshold 和 Max Voice Instances
为便于 Wwise 确定何时将实声部转为虚声部,我们需要指定 Volume Threshold。Volume Threshold 决定在低于多小的音量时可将声音安全地转为虚声部。
各位可针对各个平台在 Project Settings 的 General 选项卡中加以定义:
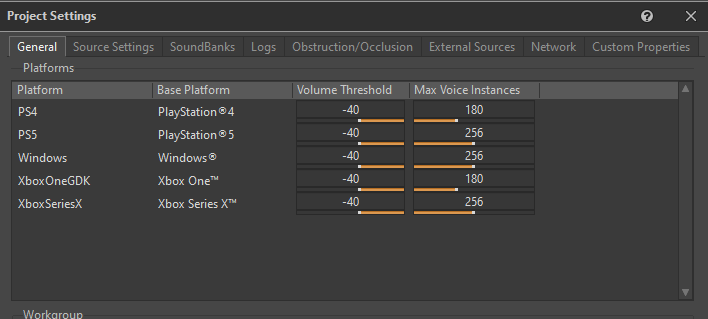
图 22 - Project Settings 窗口的 General 选项卡
就虚声部行为而言,我们觉得将 Volume Threshold 设为 -40 比较合适。
Max Voice Instances 参数用于定义各个平台允许的最大实声部数。如果实声部的数量超出此限值,会根据优先级将其余声部发送到虚声部。为了更好地控制游戏中的声部数,我们为该参数设定了相对宽松的值。
在对声部实施性能分析时,要注意监控两项参数:Number of Voices (Physical) 和 Number of Voices (Total)。Number of Voices (Physical) 显示游戏中同时播放的实声部总数,Number of Voices (Total) 显示注册的实声部和虚声部的总数。
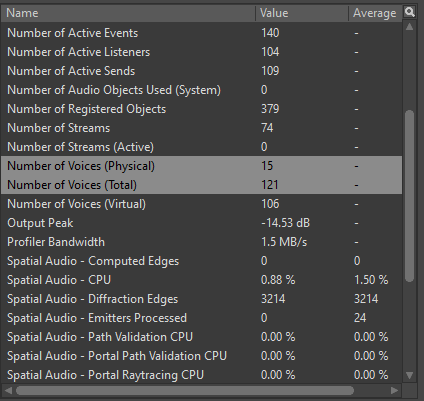
图 23 - Wwise Profiler 中的 Number of Voices 参数
如下表所示,我们为各种平台设定了允许的最大实声部数和最大声部总数:
|
实声部数(最大) |
声部总数(最大) |
|
|
Gen 8 |
30 |
500 |
|
Gen 9 |
40 |
600 |
|
PC |
40 |
600 |
表 3 - 各种平台的最大声部数
虽说虚声部的计算要求比实声部低很多,但在游戏中仍要避免使用过多的虚声部。另外,虽然虚声部占用的资源相对少一些,但仍需计算音量以及处于虚声部状态的时间。更重要的是,虚声部仍会被视为发声体 (Emitter)。如果发送到 Spatial Audio,会影响 Diffraction 路径计算。
- Playback Limit
如果无法预测声音可能会被触发多少次,或者同时播放的同一声音的实例过多,可在 Wwise 中为该声音应用 Playback Limit。
Playback Limit 选项设在 Property Editor 的 Advanced Settings 选项卡中。在此,可将 Limit sound instances to 设为特定数值。除此之外,还可灵活选择限值的作用范围。选择 Game Object 可限制各个 Actor 的声音,选择 Global 则可统一限制整个游戏的声音。
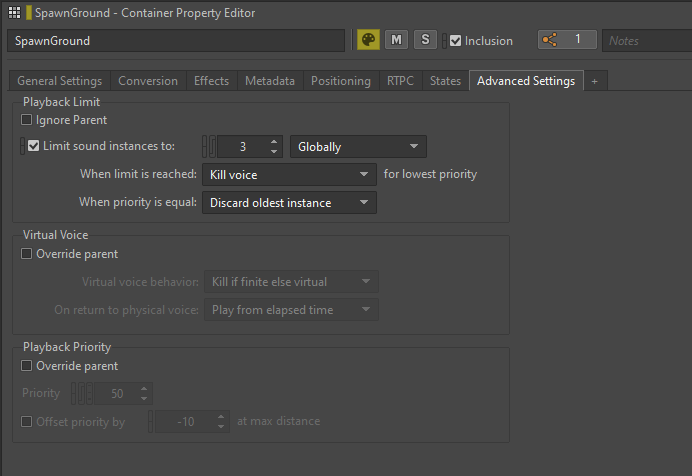
图 24 - 限制 Random Container 的声音实例
我们主要将声音实例限制用在了 Enemy 声音上,尤其是在激烈的战斗场景中。这时会多次生成同一敌人类型,并可能同时触发很多类似的声音。通过应用 Playback Limit,我们不仅优化了游戏的性能,还通过减少过多的声音交叠改善了整体混音效果。
AkComponent
AkComponent 源自于 USceneComponent,代表 Unreal Engine 中的活跃 Wwise Event。
从声音设计师的角度来说,我们可以将 AkComponent 看作游戏中的音频源或扬声器。在出现在游戏中时,这些扬声器可发出声音,绑定到 Actor 上,甚至还能随之移动。
有效管理游戏中的 AkComponent 是优化音频性能的关键一步。对于每个活跃的 AkComponent,在每一帧都需要执行各种计算。所以,注册的 AkComponent 数量过多的话会占用大量 CPU 资源。
为了对声音的发送加以优化,我们要尽可能利用现有的 AkComponent,而不是为每个 Event 生成新的组件。通过追踪游戏中的所有 AkComponent,并根据需要在现有 AkComponent 上发送声音,我们可以减轻 CPU 的总体负荷。
AkComponent 尤其适用于游戏中持续存在并会移动的角色(如 Player Character、NPC、Enemy、Projectile 等)。有些 Actor(如 AkAmbientSound)可能已经默认绑定了 AkComponent。
- 改为使用 Post Event at Location 发送 Event
Wwise 中的 Post Event at Location 函数不需要 AkComponent 就能发送 Event。该函数将 Event 和变换数据作为输入,使用指派的 ID 编号注册临时的 Wwise 游戏对象,并基于变换的位置和方向发送 Event。
跟创建 AkComponent 并通过其发送 Event 相比,使用 Post Event at Location 函数的成本要低很多。Wwise 游戏对象一般只携带很少的信息,但其行为跟在 AkComponent 上发送声音还是很像的。主要区别在于,在 Wwise 游戏对象上发送 Event 后不能更改其变换数据,不能绑定到另一 Actor,不能使用 Wwise Switch、State 或 Callback,也不能通过作用域为 Game Object 的游戏参数予以修改。
尽管存在以上种种限制,但在特定位置发送 Event 对很多不同类型的声音还是有很多好处的。这种设置通常用于发送带有定位的一次性声音或循环。除此之外,不与任何 Actor 或位置绑定的无定位 2D 声音也可使用此函数来发送;这些声音会忽略变换数据。
在《Scars Above》中,我们将 Post Event at Location 广泛应用于了 UI 音效、乐曲、游戏世界中的互动、撞击事件(包括某些击中敌人的声音)、静态 Actor 发出的循环声音等。除此之外,还可将 Post Event at Location 函数用于全局作用域的实用程序事件(如设置全局状态、更改全局混音或暂停/恢复总线等)。
在使用 Post Event at Location 时,有几点需要注意:
1. 要获取想要的声音位置,可搜索提供位置的组件或 Actor。另外,还可使用 Get World Location 或 Get Actor Location 等函数检索位置数据;
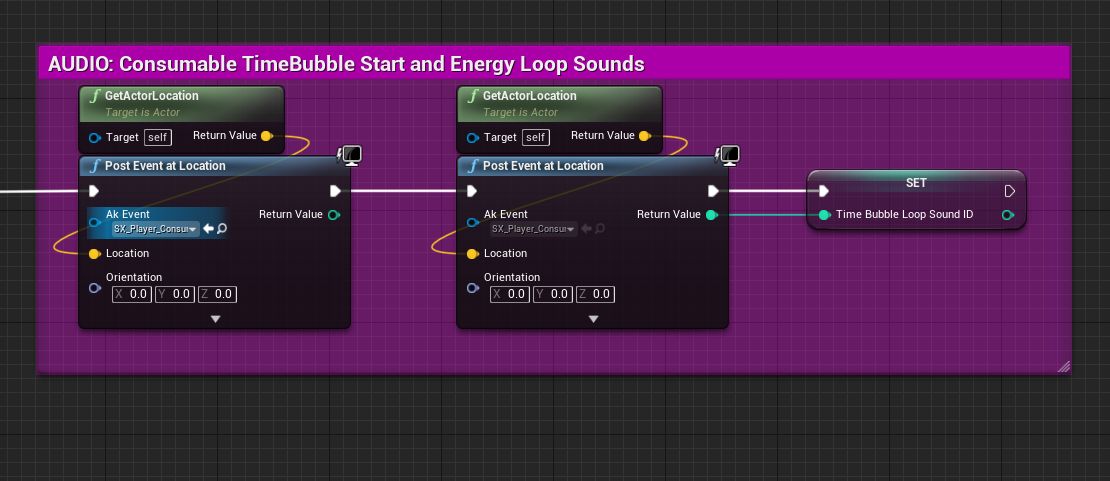
图 25 - 基于 Actor 位置发送带有定位的声音
2. 如果要在 BeginPlay 时发送声音,请确保在发送 Event 前加载 Spatial Audio Actor。这样可确保在 Spatial Audio 网络中正确地定位声音。与 AkComponent 不同,在加载 Spatial Audio Actor 时,游戏对象上发送的 Event 不会更新其相对于 Spatial Audio 的位置。
3. 在游戏对象而非 AkComponent 上发送循环声音时,还要处理停止循环声音的问题。在销毁 AkComponent(比如卸载父级 Actor)时,会停止所有通过其输出的声音。不过,为 Post Event at Location 函数创建的临时游戏对象跟此类游戏逻辑并无关联。要停止这些声音,可注销相应的游戏对象或手动停止 Event。就停止游戏对象 Event 来说,最简单方法是以 Game Object ID 作为输入来调用 Execute Action on Playing ID 函数。
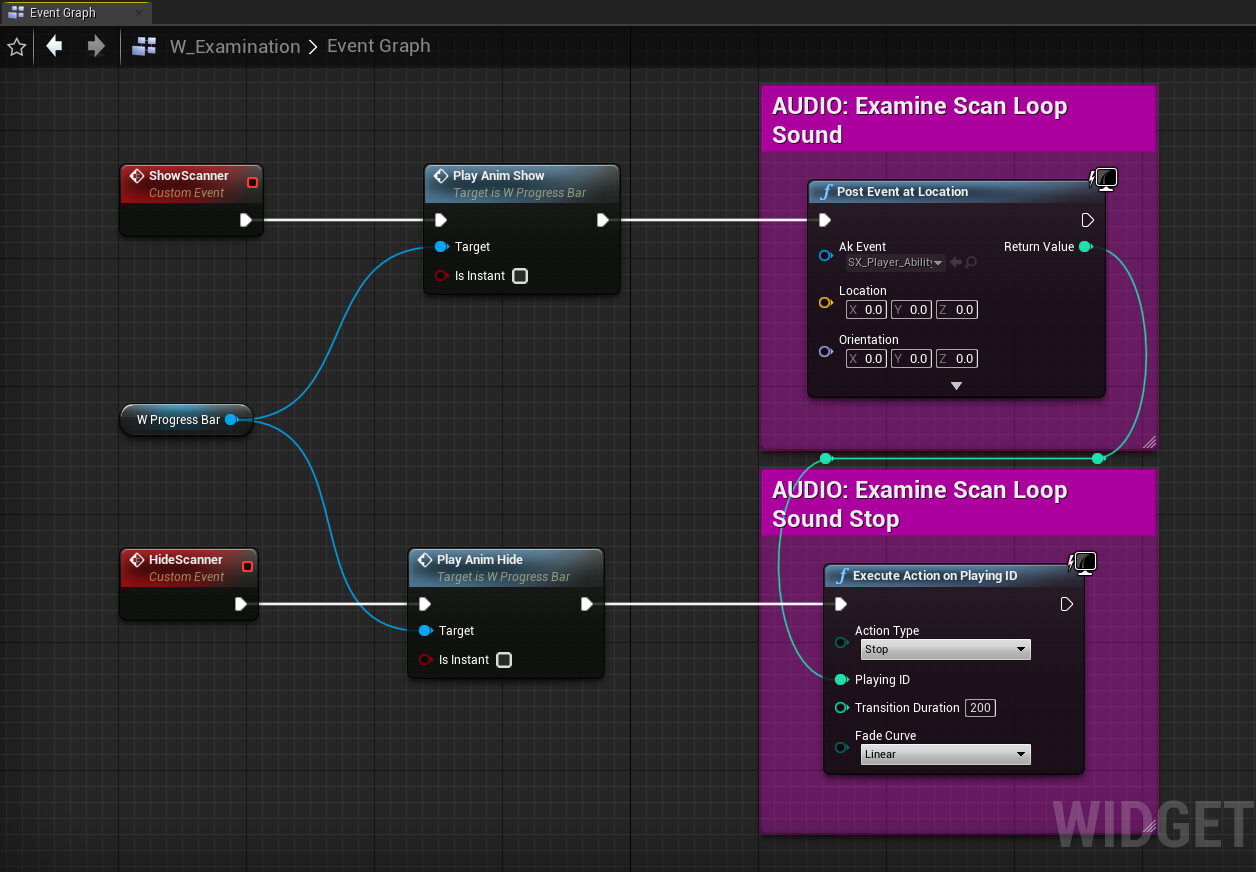
图 26 - 发送和停止不带定位的 UI 音效
Animation Notify
我们经常会通过直接在动画中发送 Event 来在游戏中触发声音。虽然大多数声音都在同一 AkComponent 上发送,但有时通知太多会导致很多声音同时播放,最终生成大量的实声部。
通过将声音分成小的片段或多个分层,可获得更高的保真度并更好地控制与运动的同步。但是,如果接连发送这些声音,可能会触发过多的 Event,导致大量调用 Wwise,尤其是在同时播放多段类似动画时。
将过场动画混合在一起会使问题进一步恶化,因为混合两段包含大量通知的动画可能会触发更多 Event。
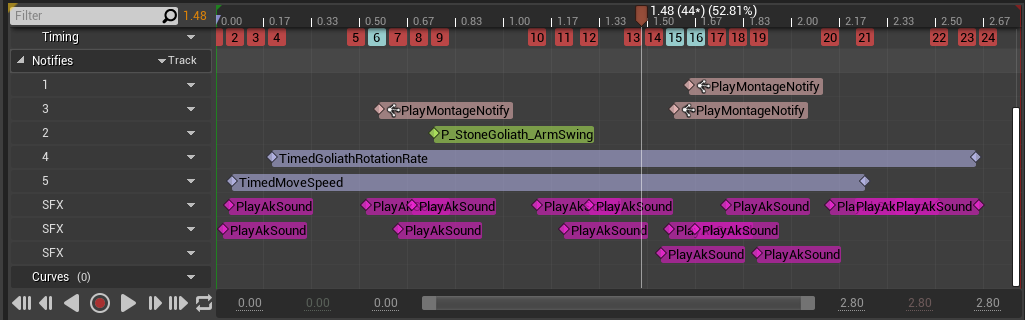
图 27 - Animation Montage 包含大量声音通知
在这种情况下,我们要搞清楚每一段动画是否真的有必要包含那么多通知,并考虑能否用较少的音频 Event 达到相当或相同的品质水平。通过减少动画中同时播放的声音数量,可以减少活跃声部数并减轻 CPU 负荷。
通过组织素材优化性能
组织素材对提升工程的性能并完善整体工作流程来说非常关键。通过将素材放到适当的 SoundBank 和子关卡中,我们可以控制何时加载和卸载这些素材。这样便于更加有效地管理资源的使用情况,确保任何时候都只将必要的素材加载到内存中。
另外,工程要保持整洁,没有多余的素材。通过删除不必要的素材可让界面更有条理,还可最大限度地减少内存和 CPU 的消耗。
SoundBank
为了有效地管理游戏的音频内存,可将声音分组到存放到 SoundBank 中。在大多数情况下,没必要在任何时候都加载所有的声音。为此,可将声音分组并只在需要时加载。这样不仅可以减轻内存负荷,还能清楚地了解何时以及如何加载和播放声音。
为了能正确加载不同类型的声音,我们决定将其分为以下几个类别:
- Main:包含整个游戏中都会用到的 Event;
- Player:包含所有 "Player" Event;
- Enemies:每个 Enemy 类型对应一个 SoundBank,其中包含所有与该 Enemy 相关的 Event;
- CharactersCommon:包含所有共用的 "Character" Event;
- Levels:每个 Level/Sublevel 对应一个 SoundBank,其中包含所有与该 Level/Sublevel 相关的 Event;
- LevelsCommon:包含所有共用的 "Level" Event;
- Music:包含所有 "Music" Event;
- Voice:包含所有 "Dialogue" Event;
- EmotionalResponses:包含所有 "Player Emotional Responses" Event;
- Cinematic:包含所有 "Cinematic" Event;
- HapticFeedback:包含所有 "Haptic Feedback" Event。
- 自动加载 SoundBank
对于设为 Auto-Load 的 SoundBank,系统会在游戏引用该 SoundBank 中所含的 Event 时自动予以加载。"Main"、"Player" 和 "Music" 等 SoundBank 会不断被引用,并在整个游戏过程中保留在内存中。对于 "Enemies" SoundBank,系统会追踪每种敌人类型在何时何处被引用,并依靠自动加载机制动态加载和卸载特定于各 Enemy 类型的 SoundBank。
在我们的工程中,"Levels" SoundBank 以外的所有 SoundBank 都被设为了 Auto-Load。对于 "Levels" SoundBank,我们希望能严格控制 Actor 和 Event 的加载时机和位置。为此,我们将 "Levels" SoundBank 的加载跟 "World Composition" Level Streaming 系统绑定在了一起。这样就可根据需要加载和卸载特定的关卡(我会在本节稍后部分介绍 Level Streaming)。
- "Common" SoundBank
为了存储不同 Character 或 Level 之间共用的 Event,我们创建了 "Common" SoundBank 并将其设为了 Auto-Load。"Common" SoundBank 的好处是,共用媒体只会加载一次,而不是在多个 SoundBank 中重复加载。这样可以减轻内存负荷。不过,因为 "Common" SoundBank 未与特定的 Character 或 Level 绑定,所以跟自动加载或流式加载相比,"Common" SoundBank 的持续加载时间更长一些。
在使用共用的 Event 时,当然也可选择在不同的 SoundBank 中重复加载媒体。虽然这可能会导致有时在多个 SoundBank 中加载相同的 Event,但若处理得当,跟 "Common" SoundBank 相比,时间会短很多。
最好使用 "Common" SoundBank 来存储已知会被多个不同 Character 或 Level 同时引用的 Event。比如,在同一区域遇到不同敌群,而其共用若干相同的声音。在知道不会在多个 SoundBank 中同时加载重复使用的 Event 时,另一种方法会比较合适。比如,"Levels" SoundBank 通常就是这种情况。不过,最终还是要由声音设计师根据项目需要和具体情况决定何时以及如何加载共用和特定的 SoundBank。
- Event-Based Packaging / Auto-Defined SoundBank
《Scars Above》是使用原有的 SoundBank 系统开发的。不过,我们准备在今后的所有项目中改用经过改进的 Auto-Defined SoundBank。Auto-Defined SoundBank 是 Wwise 2022.1 中引入的功能,其基于 Event-Based Packaging 概念,旨在替代原有系统。其主要原理是将每个 Event 视为一个独立的极简 SoundBank,确保只在该 Event 被引用时予以加载并在播放结束后卸载。
在制作《Scars Above》的过程中,我们曾尝试改用 Event-Based Packaging,但在实施过程中遇到了很多问题。虽然理论上很有应用前景,但实际上 Event-Based Packaging 功能还不够完善。所以,我们才决定在《Scars Above》中使用原有的 SoundBank 系统。
Level Streaming
借助 Level Streaming,可确保只将关卡中真正需要的 Actor 加载到内存中。这样可以减少同时加载的 Actor 数量,从而减少占用宝贵音频线程的发声体和游戏对象。
对于关卡中发送到 Spatial Audio 的每个发声体,只要听者 (Listener) 移动就需要计算衍射路径。每一帧都是如此。所以,加载数百个发声体会导致出现大量 Spatial Audio CPU 峰值(见图 3)。
我们可以随时在 Wwise Profiler 中查看当前活跃的发声体数。根据我的分析,建议在 Gen 8 平台上将发声体数(Profiler 中的 Spatial Audio - Emitters Processed 值)控制在 150 以下,在 Gen 9 和 PC 平台上控制在 200 以下。
就减少发声体数来说,最好将地图分为小的子关卡,确保只在必要时加载发声体。通过将 Actor 分为特定的 Sound Sublevel,可控制在哪些区域加载该关卡中的 Actor。在 Player 进入指定区域时,会加载该子关卡中的 Actor;在 Player 离开该区域时,会卸载相应的 Actor。具体到《Scars Above》中,我们使用了根据 Level Bounds 加载和卸载关卡的 World Composition 系统。
- World Composition
简单来说,World Composition 是个用来管理大型地图的系统。它会将地图分为小的子关卡,并组织成 Stream Layer。每个子关卡都有对应的 Level Bounds 方框,并会根据 Stream Layer 指派以 Unreal 单位表示的 Streaming Distance 值。此距离决定要在 Level Bounds 方框周围的哪部分区域加载子关卡。比如,如果 Level Bounds 方框的 Streaming Distance 为 1500 个单位,那么只要 Player 在边界的 1500 个单位内或在方框内就会加载关卡。
该系统可有效地将地图分为易于管理的小块,并以此确保只在给定区域加载需要的 Actor。虽然向虚声部系统发送声音可释放部分 CPU 处理资源,但 Actor 本身仍处于加载状态,相应游戏对象还是会被注册用于音量和 Spatial Audio 计算。另外,将过多的此类对象加载到内存中还会导致出现 CPU 峰值。
- 我们是如何拆分关卡的
在将一个关卡拆分为小的子关卡时,最直观的做法是按照地图上 Actor 所属的具体区域对其进行分组。区域代表在听觉和视觉上有明显区别的关卡部分。就素材组织和命名来说,我们可以将其看作独立的地带。
每个区域都有一个专门的 Sound Sublevel。在区域比较复杂或者规模较大的时候,最好将区域进一步拆分为更小的关卡。

图 28 -《Scars Above》中的沼泽生物群落及 Sound Sublevel 边界
- Level Bounds
在启用 World Composition 后,可定义每个子关卡的 Level Bounds 以用于 Level Streaming。在 World Outliner 中,可找到该关卡的 "Level Bounds" Actor 实例。这些 Actor 由透明方框表示,其决定了每个子关卡所覆盖的区域(这种基本形状无法更改,所以我们只能使用方框)。在设置边界时,必须注意 Level Bounds 方框有没有将该子关卡中的所有声音和 Actor 涵盖在内。
在确定边界时,最好的办法是选中关卡中的所有 Actor 并察看其所覆盖的区域。通常,我们会查看 "AkAmbientSound" Actor 的衰减半径,因为其所覆盖的关卡区域是最大的。

图 29 - 选中子关卡中的所有音频 Actor
然后,要根据衰减半径所构成的球体调整 Level Bounds 以使其涵盖所选 Actor。
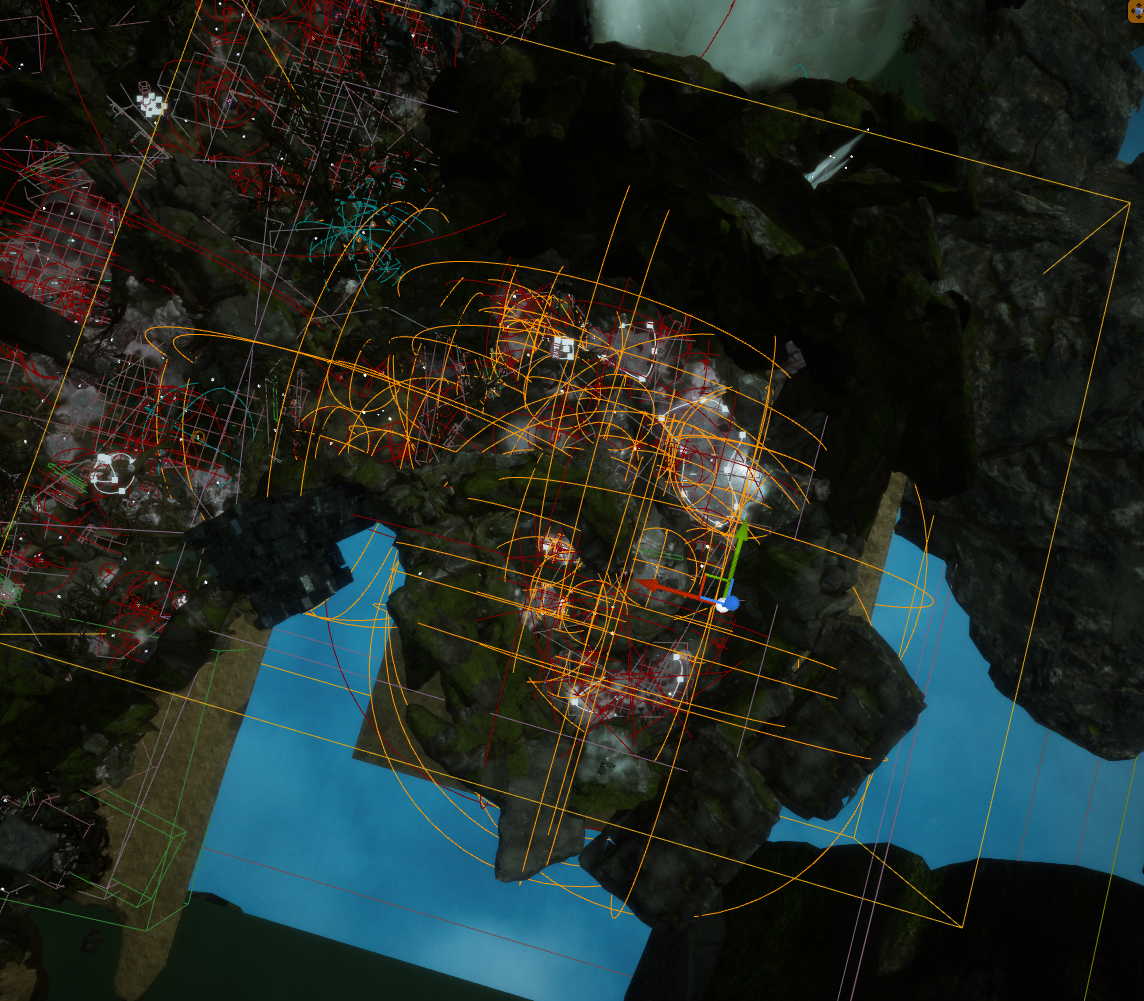
图 30 - Level Bounds 方框涵盖子关卡中的所有音频 Actor
- Stream Layer
要让子关卡正确地流传输,需将其指派给 Stream Layer。为此,可在 Levels 窗口中选中子关卡,并选择相应的 Stream Layer。
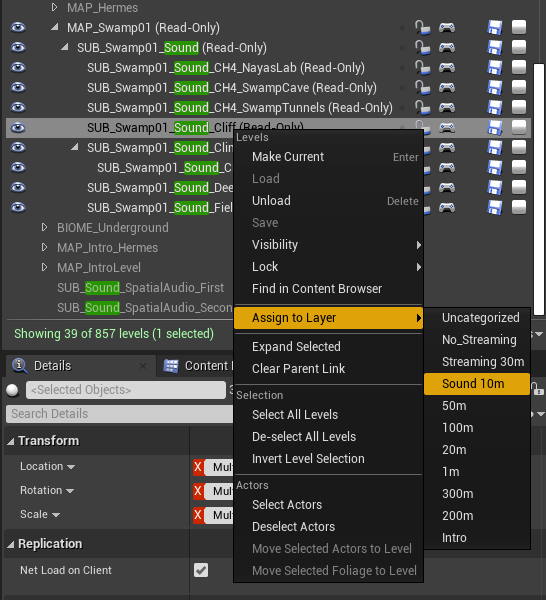
图 31 - 将 Sound Sublevel 指派给相应的 Stream Layer
在 World Composition 窗口中选择 Stream Layer 后,可在顶部视角下查看指派给该分层的所有关卡的边界。
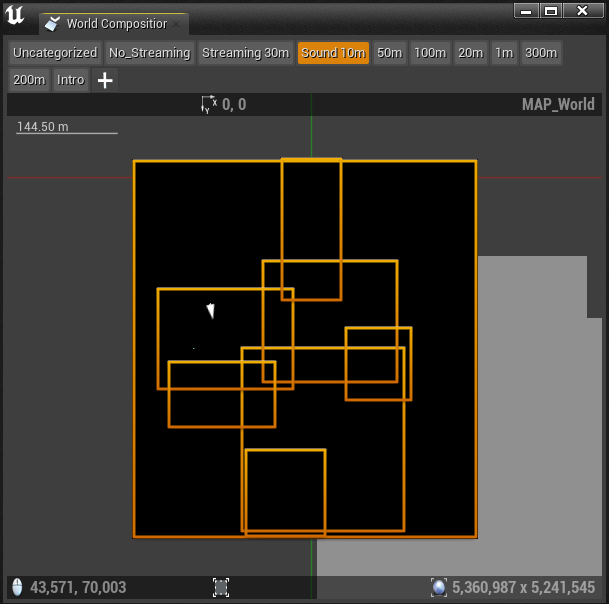
图 32 - World Composition 窗口显示指派给 "Sound 10m" Stream Layer 的子关卡
- AntiLevelStreaming
现在各位可能也发现了,使用简单的方框形状覆盖要加载的 Actor 区域并非优化子关卡加载和卸载的最佳方案。因为只能使用很简单的形状(如方框),所以没有办法精确定义子关卡的边界。这就产生了一些问题。地图上可能存在并会同时加载多个关卡之间有重叠的区域。因为 "Level Bounds" Actor 是方框形状,所以我们没有办法从区域中排除关卡。
在填充有很多 Actor 的区域,即便正确放置了 Level Bounds,有些地图区域仍有可能同时加载过多 Actor。
为了解决这些问题,我们的编程团队构建了名为 AntiLevelStreaming 的定制解决方案,以此弥补 World Composition 的不足之处。
通过在地图上添加 AntiLevelStreamingActor 实例,可创建跟 Level Bounds 非常类似的边界框,并指定希望在进入这些边界框时从 Level Streaming 中排除(即卸载)哪些定子关卡。通过将这一系统与 World Composition 结合使用,我们成功解决了将过多子关卡加载到内存中时区域存在的 Level Streaming 问题。
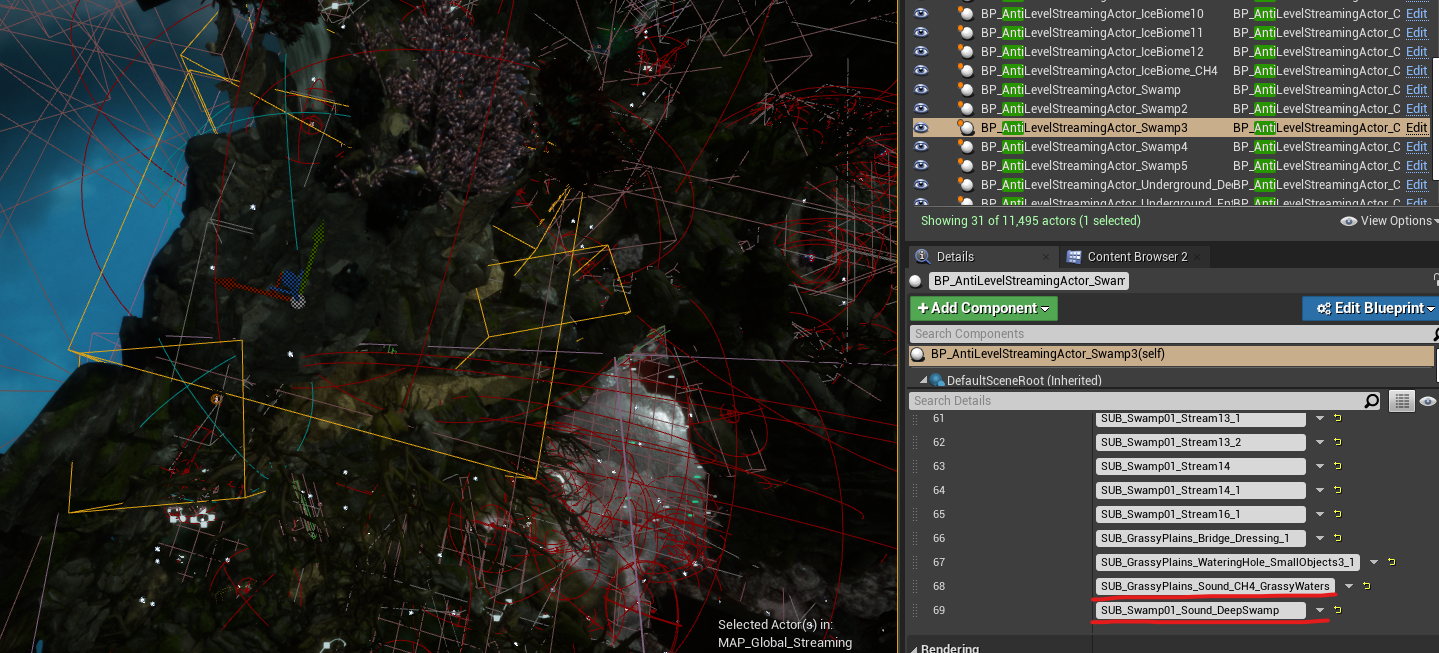
图 33 - 在 AntiLevelStreamingActor 上添加 Sound Sublevel
- 对 Spatial Audio 进行流传输
遗憾的是,Spatial Audio Actor 无法进行流传输。通过测试我们发现,在加载和卸载 Spatial Audio Volume(尤其是 AkAcousticPortal)时会做大量的重新计算。这对 CPU 造成了很大的负担。
在测试当中,我们发现在运行时动态加载和卸载 Spatial Audio Volume 和 AkAcousticPortal 会对 CPU 性能产生很大影响。对于流传输的每个 Spatial Audio Actor,都要重新计算所有活跃 Actor 的衍射路径。所以,将 Spatial Audio Actor 与其他音频素材一起进行流传输并不现实。
为了解决这一问题,我们决定创建一个包含所有 Spatial Audio Actor 的持续性 Spatial Audio 子关卡。该子关卡始终处于加载状态,并不受 Level Streaming 影响。
由于 Spatial Audio 几何构造过多,这反过来又在制作后期造成了一些问题。有一次,我们在一个持续性子关卡中使用了几千个 Spatial Audio Actor。对此,可将这个子关卡拆分为两个小的子关卡,并只在游戏的遥远区域之间过渡时加载它们。鉴于过渡是由加载屏幕处理的,我们有充足的时间在不影响玩家体验的情况下正确加载和卸载所需的 Spatial Audio 子关卡。
移除不必要的素材
在任何长期项目中,功能都会过时或发生重大变化。在团队确定切实可行的解决方案之前,会经过多次的迭代和优化。为这些功能定制的声音可能不再适用,这个时候就需要创建新的声音。
在有很多人参与开发同一项目时,追踪声音的所有改动和版本有时并不可行,有些声音可能会在声音设计师不知情的情况下变得多余。为了优化内存资源,必须找到并删除不必要的 Event。
要查明 AkEvent .uasset 有没有被使用,最简单的方法是检查它的引用情况。如果 Event 只引用了与其对应的 SoundBank,就意味着很可能没有正确实现或者用不着了。在这种情况下,建议将不必要的 Event 从 SoundBank 移到 Unreal Editor 和 Wwise 中的 Unused 文件夹中。这样可确保其不会占用游戏内存,但在将来需要的时候还可以访问。
图 34 - AkEvent 只引用了与其对应的 SoundBank
Spatial Audio
Spatial Audio 很复杂,在这里我就不细说了。不过,我在之前的博文中详细介绍了 Spatial Audio,包括如何优化 Spatial Audio。
点击以下链接查看该博文的“优化”章节:优化
在本章节,我将介绍有关如何充分优化 Spatial Audio 的各项必要细节。
总的来说,优化 Spatial Audio 的关键步骤包括:
- 留意三角形的总数,并尽可能简化几何构造;
- 尽量减少 Volume,尤其是 AkAcousticPortal;
- 在所有凸起的 Volume 上禁用 Surface Reflector;
- 注意每一帧处理的发声体总数;
- 调整各个平台的 Spatial Audio 初始化设置。
如果想了解更多有关 Spatial Audio 的信息,建议仔细阅读该博文并参阅官方 Audiokinetic 文档的相关主题。
进一步调整(在用尽其他解决方案后)
如果前面的解决方案都没有解决您面临的问题,可考虑通过其他一些步骤进一步提升游戏性能。
将 "Stop" Event 替换为 Execute Action on Event/Playing ID
对于有些类型的声音,需要创建并使用专门的 "Stop" Event。
不过,也可选择使用现有的 Blueprint 函数 Execute Action on Event 或 Execute Action on Playing ID。这些函数提供了诸如 Stop 或 Pause 等操作,可替代某些负责停止或暂停声音的 Event。通过使用这些 UE 函数而非专门的 Event,可从 SoundBank 中完全移除这些 Event。这有助于减轻工程的内存负荷,当然效果可能并没有那么明显。不过,能提升游戏的性能总是好的。
尽量用文件夹替代 Actor-Mixer
在 Wwise 工程中,如果只用 Actor-Mixer 来组织声音,但没有对这些 Actor-Mixer 做实际的更改,那么直接用简单的文件夹替代它们也能达到同样的效果。这样可以减少要对这些声音所做的计算,因为少了一个层级结构能省掉很多麻烦。
跟替换 "Stop" Event 一样,相较于其他优化技术,这种方法可能并不会带来明显的改善。不过在有些情况下,任何一点优化都很宝贵。
减少 Random Container 内的变化版本数
如果在某个平台上达到了设定的限值,可选择弃用部分素材来减轻内存负荷。对 Random Container 来说就是如此。在该容器中,可选择减少专门用于该平台的某个声音的变化版本,同时为其他负荷没那么重的平台保留原有变化版本。
要弃用 Random Container 中的变化版本,可取消链接特定变化版本的 Inclusion 选项,并将该声音排除在希望优化的平台之外。这样可以减少这个平台上的内存用量,同时在其他平台上保留各种原有变化。
结语
感谢各位阅读这篇博文。综上所述,优化游戏音频对提升整体性能和减轻内存负荷来说非常重要。借助本文所述的各种优化技术,我们有望提高玩家的整体满意度,为其提供无缝衔接的视觉和听觉体验来让其完全沉浸于游戏之中。
首先,非常感谢 Dimitrije、Teodora、Selena、Marko 和 Petar,他们是我在 Mad Head Games 的声音设计师同事,还有 EA Dice 的 Nikola,感谢他提供的支持和反馈。同时,衷心感谢我们的音频程序员 Artem 以及 Mad Head Games QA 团队的 Olja、Lazar、Stefan 和 Borislav。另外,还要感谢 Audiokinetic 的 Julie、Masha、Maximilien 和 Damian 提供的反馈,并让我有机会以博文的方式表达自己的想法。
实用链接
Wwise-251 认证课程
https://www.audiokinetic.com/zh/courses/wwise251/
有关性能分析的文档
https://www.audiokinetic.com/zh/library/edge/?source=Help&id=profiling
Wwise Profiler 参数概述
https://www.audiokinetic.com/zh/library/edge/?source=Help&id=performance_monitor_settings#profiler_counters
有关 Voice Starvation 的文档
https://www.audiokinetic.com/zh/library/edge/?source=Help&id=ErrorCode_VoiceStarving
有关 Source Starvation 故障排除的文档
https://www.audiokinetic.com/zh/library/edge/?source=SDK&id=streamingmanager_tips.html#streamingmanager_tips_troubleshooting_sourcestarvation
Wwise CPU 优化:通用指南
https://blog.audiokinetic.com/zh/wwise-cpu-optimizations-general-guidelines/
优化 CPU 用量
https://www.audiokinetic.com/zh/library/edge/?source=SDK&id=goingfurther_eventmgrthread.html
转码技巧和窍门
https://www.audiokinetic.com/zh/library/edge/?source=Help&id=versions_tips_and_best_practices
我之前所写博文的“优化”章节
https://blog.audiokinetic.com/zh/wwise-spatial-audio-implementation-workflow-in-scars-above/#optimization

评论