
이 블로그 시리즈는 2020년 10월 GameSoundCon(게임사운드컨퍼런스)에서 발표한 내용에 관한 내용을 담고 있습니다. 이 발표는 오브젝트 기반 오디오 렌더링 기술을 사용하여 창작자가 다음 프로젝트를 개선할 수 있는 관점과 도구를 제공하기 위해 마련되었습니다. 이러한 기술은 우리가 자연에서 소리를 경험하는 것과 최대한 비슷하게 소리의 공간화를 재현합니다.
발표 내용은 세 가지 부분으로 구분되어 있습니다:
- 이 글에서 살펴보게 될 첫 번째 부분은 오디오 전문가가 오브젝트 기반 오디오를 사용하여 프로젝트를 저작할 경우 여러 개의 시스템과 재생 종단점에서 어떻게 더 나은 결과를 가져다주는지 보여줌으로써 채널 기반 오디오에 비해 이 접근 방식의 장점을 소개해줍니다.
- 두 번째 부분은 모든 믹싱 고려 사항에 대한 작업 과정을 향상하면서 오디오 오브젝트를 완전히 활용하는 종합적인 저작 환경을 제공하기 위해 Wwise 2021.1 버전이 어떻게 변화되었는지를 설명해줍니다.
- 마지막으로 세 번째 부분은 최근 프로젝트에서 오디오 오브젝트를 사용한 사운드 디자이너와 작곡가들이 사용한 여러 가지 방법, 기술, 비결을 소개해줍니다.
공간화 인코딩하기 - 역사적 개요
재현을 위한 오디오 인코딩은 수백 년이 넘도록 사용되어 왔습니다. 수십 년간 이런 인코딩은 설계적으로 공간화를 제공하지 않는 모노로 수집되었습니다 (하지만 어떤 사람들은 모노 녹음이 공간화의 형태인 깊이감을 쉽게 수집할 수 있다고 주장할 수 있습니다). 1970년대가 되어서야 스테레오 시스템이 보편화되면서 공간화가 담긴 음악의 재현을 대중에게 선사할 수 있게 되었죠. 스테레오 형식이 일반적으로 수용되면서 사운드 엔지니어와 음악 애호가들은 소리의 공간화와 방향성을 위해 믹싱을 하고 대화를 하기 시작했습니다.
1980년대에 들어서고 나서는 VCR(비디오 카세트 녹음기)이 널리 보편화되고 VHS(가정용 비디오 방식)로 영화를 대여할 수 있게 되면서 업계에서 영화관에서의 경험을 가정에 제공하기에 관한 아이디어가 모이기 시작했습니다... 물론 일반 대중이 새로운 사운드 시스템 구성을 구매한다는 전제하에 말이죠! 바로 이렇게 해서 LCRS (좌-중앙-우-서라운드)에서부터 전체 역동성과 주파수 범위를 제공하는 올바른 5.1 스피커 구성뿐만 아니라 7.1까지 발전할 수 있었고, 현재 높이 채널이 추가된 7.1.4까지 생겨날 수 있었습니다. 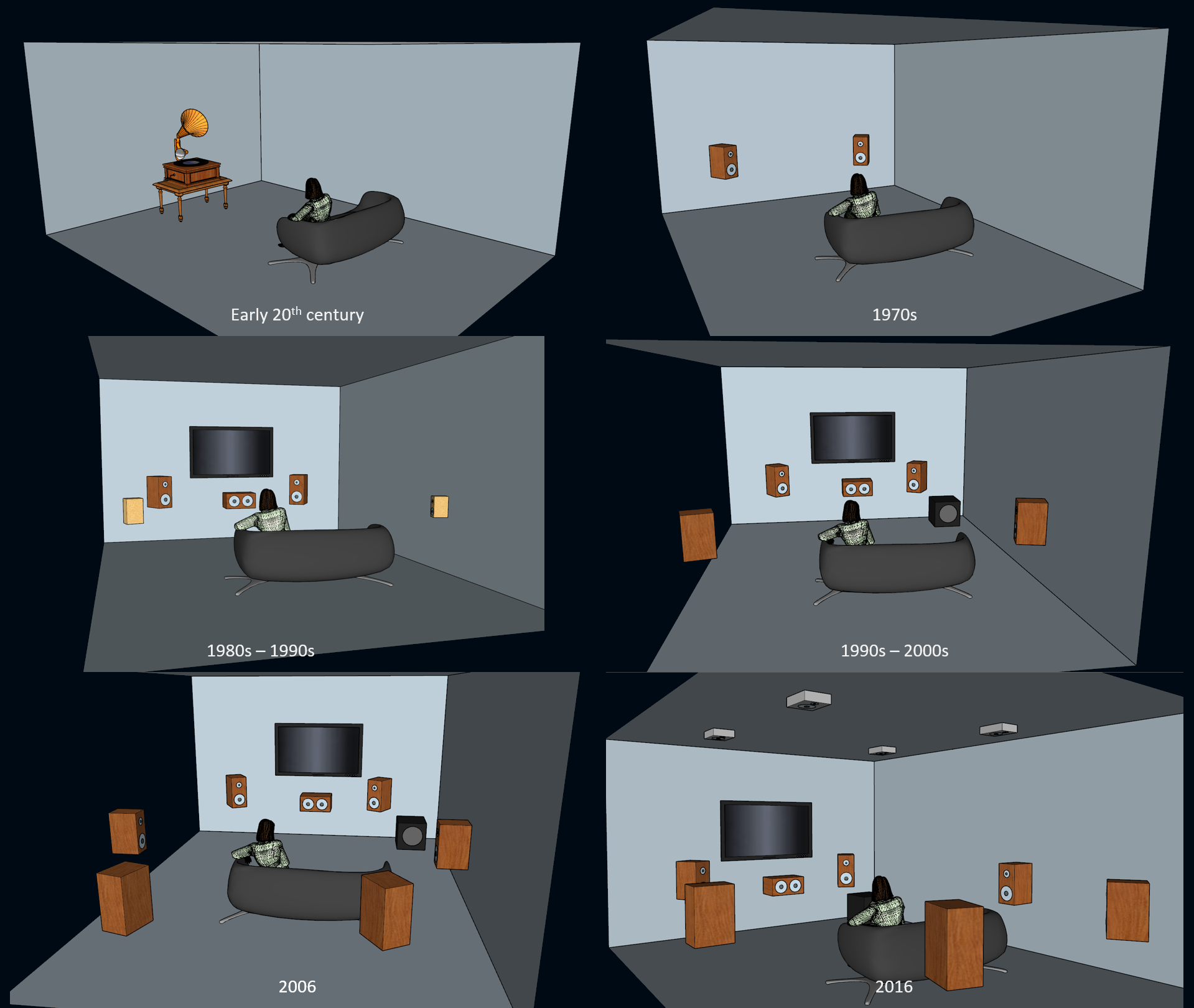
공간 음향 재현의 소비자 환경 진화
하지만 지난 10년동안 일반적인 라이프 스타일에서 유동성이 더욱 중요해지면서 거실에 스피커를 더 추가하기 보다는 헤드폰 사용이 늘어나게 되었습니다. 이 변화에는 모바일과 멀티플레이어 게임의 보편화가 크게 기여했죠. 스피커 대 헤드폰 판매량과 향후 몇 년 동안 시장의 예산 규모를 살펴보면 앞으로도 사람들이 계속해서 헤드폰을 통해 게임 음향을 재생할 것이라는 것을 쉽게 알 수 있습니다.
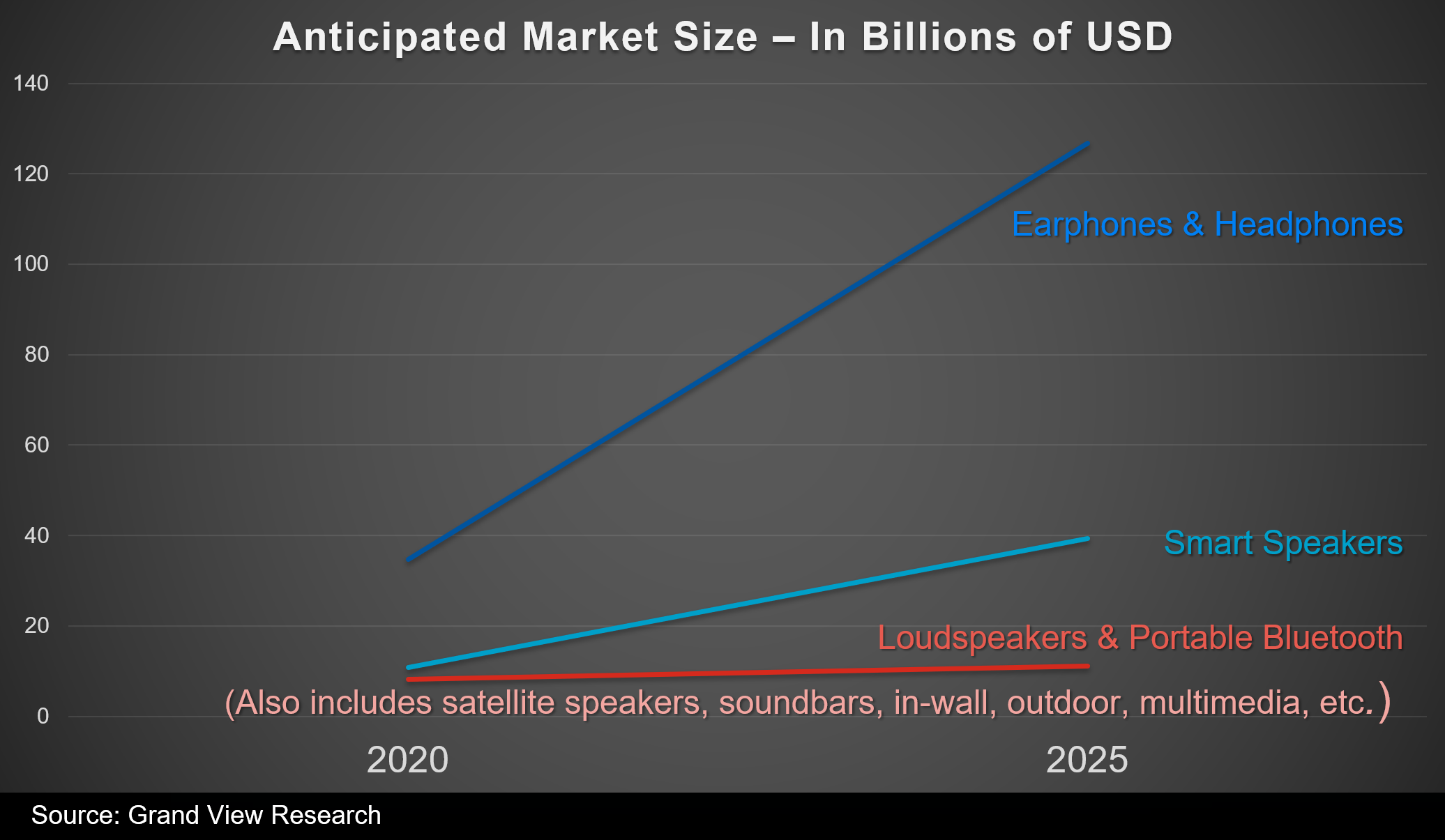
향후 5년 간 이어폰과 헤드폰의 예상 판매 목표 및 성장이 스피커보다 우위를 차지하고 있습니다
공간에서의 오디오 인지
합성된 오디오를 스피커나 헤드폰에서 생동감있게 전달하려면 두 가지 요인이 공존해야 하며 서로를 보완해야 합니다:
- 도구와 기술: 오디오 재현 기술이 소리의 물리를 최대한 정확하게 시뮬레이션해야 합니다.
- 인간으로서의 경험: 성능이 인간으로서 우리의 기대에 부응해야 합니다.
이 두 가지 요인을 좀 더 자세히 살펴볼까요?

기술과 인간으로서 우리의 경험은 우리가 공간 안에서 합성된 사운드를 자연에서와 경험하는 것처럼 인지하는 데에 작용하는 두 가지 요인입니다.
방향성 재현하기
HRTF (Head-Related Transfer Function, 머리 전달 함수)는 보통 헤드폰에서 소리의 방향성이 아주 높은 수준으로 정확해야 할 경우 사용할 수 있는 최고의 기술입니다. 소리의 방향성을 정확하게 재현하기 위해서 HRTF 알고리즘은 다음의 인지적 신호를 활용합니다:
- ITD (Interaural Time Difference, 두 귀의 시간 차): 두 귀 간에 한 소리가 도착하는 시간 차를 말합니다. 이 시간 차는 1 밀리초도 되지 않지만 우리 뇌가 방향성을 감지하기에 충분하죠.
- IID (Interaural Intensity Difference, 두 귀의 강도 차): 두 귀 중 하나에서 머리로 인해 방해 효과가 일어나고 이에 따라 상대적 진폭이 생겨나면서 두 귀 간에 음색과 위상이 달라지는 현상을 말합니다. 이 효과는 신호의 주파수에 따라 두드러짐에 차이가 있습니다.
- Spectral Cue(스펙트럴 신호): 서로 다른 방향에서 오는 동일한 소리가 주파수에 따라 고막에서 서로 다른 피크(치솟은 부분)와 노치(파인 부분)의 패턴이 생기는 현상을 말합니다.
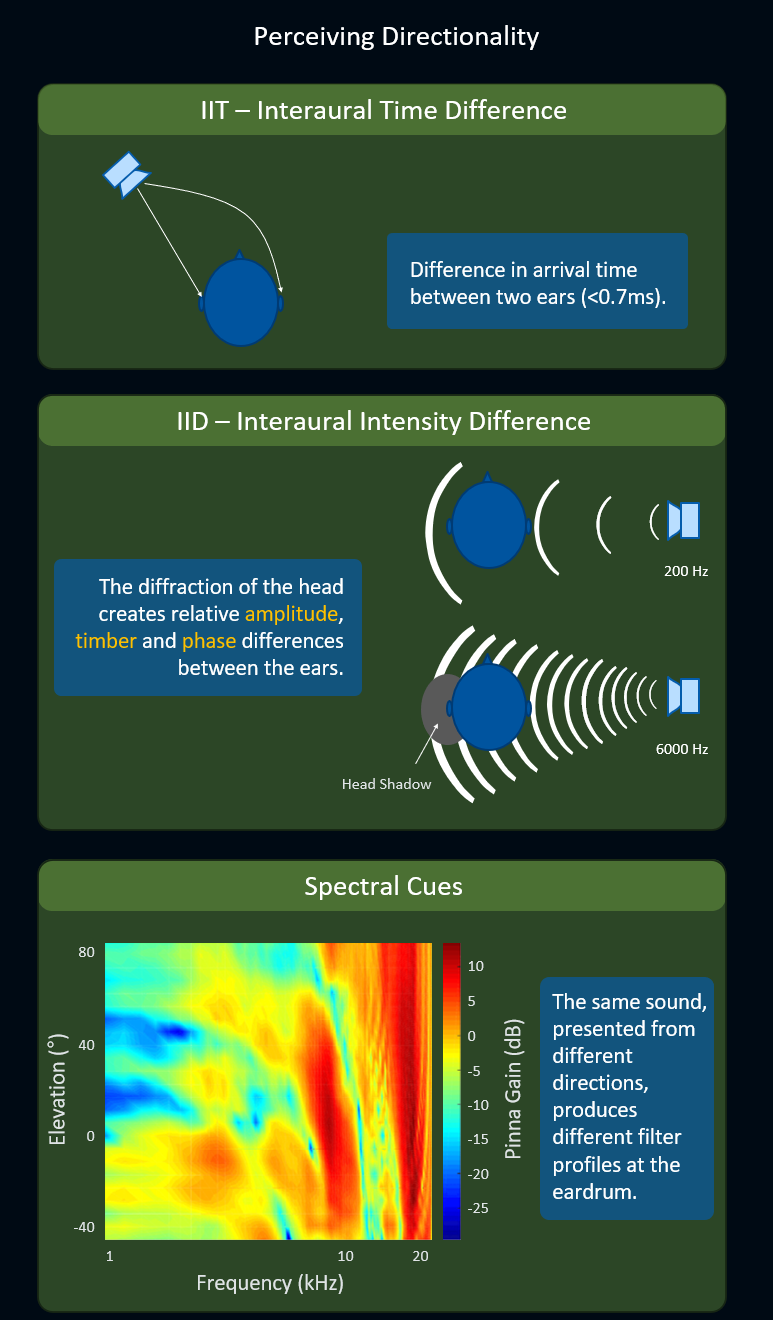
ITD, IID, Spectral Cue 기술을 사용해서 리스너 주변으로 공간화된 소리의 정확도를 향상시킵니다. 이 글은 HRTF가 측정되는 방식을 보여줍니다.
환경 효과 재현하기
기술에 의해 재현될 수 있는 또 다른 방면은 바로 거리 감쇠, 동적 초기 반사, 후기 잔향, 소리 전달, 회절, 방해와 같은 환경 효과입니다. 이러한 현상으로부터 더 많은 요소가 사용될수록 뇌가 공간에서 소리를 인지하는 데에 필요한 더 많은 정보를 얻게 되죠. 환경 효과가 3D 공간화에 기여하는 점에 대해서는 더 말씀드릴 것이 훨씬 많지만 이 글에서는 채널 기반 오디오가 아닌 오디오 오브젝트를 사용할 경우의 장점에 집중하도록 하겠습니다.
인간으로서의 경험 요인
공간 안에서 오디오의 위치를 인지하는 우리 능력에 영향을 주는 또 다른 요인은 기술에 의존하지 않습니다. 대신 인간으로서 세 가지 방면에 대한 우리의 경험에 의존하죠.
첫 번째 방면은 '음원 재료의 렌더링'에 관한 것입니다. 예를 들어 누군가가 속삭이는 소리를 듣는다면 아마도 그 사람은 가까이에 있겠죠. 같은 말을 크게 소리치는 것을 듣는 것보다는 분명히 훨씬 더 가까이 있을 겁니다.
두 번째 방면은 '선입견과 학습된 행동'에 관한 것입니다. 예를 들어 인간으로서 우리는 헬리콥터나 비행기와 같은 특정 소리가 머리 위에서 들려온다고 생각하죠. 이것은 우리가 자라면서 시간이 지남에 따라 학습된 결과입니다.
마지막으로 세 번째 방면은 '시각적 결합'입니다. 우리의 눈은 귀가 3D 공간에서 방사되는 소리의 위치를 정확하게 파악하도록 도와줍니다. 예를 들어 시야 밖에서 소리가 들려올 때 아마도 소리가 왼쪽 어딘가에서 들려온다는 것을 예측할 수는 있습니다. 하지만 머리를 움직여서 사운드 이미터를 눈으로 확인했을 때 그제서야 공간 안에서 오브젝트가 어디에 있는지를 정확하게 알 수 있죠.
인간으로서의 경험이 우리가 공간 안에서 오디오를 인지하는 능력에 어떤 도움을 주는지에 대한 이 섹션은 브라이언 슈밋(Brian Schmidt)이 MIGS(몬트리올 상호작용 게임 서밋) 2017에서 발표한 '기술이 창의성에 끼치는 영향, 사례 연구: HRTF를 넘어서(echnology's Impact on Creativity, Case Study: Beyond HRTF)'라는 훌륭한 강의에서 자세하게 설명되어 있습니다.
채널 기반 오디오
이렇게 우리가 공간에서 소리를 어떻게 인지하며 기술을 통해 이 인지에 관한 몇몇 필수 신호를 재현할 수 있는 방법을 알아보았습니다. 그럼 이제 수년간 여러 가지 채널 기반 형식을 사용하여 레코드판, 테이프, 디지털뿐만 아니라 Wwise같은 런타임 애플리케이션에서 방향성과 환경 효과를 어떻게 인코딩해왔는지 살펴볼까요?

채널 기반 형식의 경우 방향성과 환경 효과가 애플리케이션에 의해 인코딩됩니다
채널 기반 형식에 의존하여 공간화를 인코딩하는 방식은 그 당시 사용 가능했던 기술과 계산 리소스를 고려할 때 용이한 해결책이었습니다. 하지만 이 접근 방식은 보다 정확한 공간화가 필요할 경우 여러 가지 단점을 드러냅니다. 채널 위치 간의 각도가 불균일함으로 인한 이미지 왜곡이나 진폭 소강과, 빠르게 이동하는 소리의 위상 문제나, 평면 혹은 반구를 통해서만 재현할 수 있는 구성 등이 일반적인 단점이죠. 또한 이 접근 방식은 스피커가 없거나, 올바르지 않게 배치되거나, 위상이 맞지 않게 연결된 경우와 같은 소비자 수준에서의 현실적 문제를 생각하지 않습니다.
단, 여기서 말한 단점은 사실상 채널 기반 형식인 앰비소닉에는 전혀 적용되지 않는다는 사실을 기억해주세요. 앰비소닉은 채널을 사용하여 음원의 구형 표현을 인코딩하며, 채널이 더 많을수록 오디오 장면이 더욱 정확해집니다. 다음 글은 앰비소닉 형식의 개요와 중간 공간 표현으로 사용할 수 있는 방법을 잘 설명해줍니다.
종단점이란 무엇일까요?
저희는 종단점이라는 용어를 사용하여 헤드폰이나 스피커로 전송되는 오디오의 최종 처리와 믹싱을 담당하는 시스템 장치를 설명합니다 (예: 플랫폼의 운영 시스템 수준에서 오디오를 관리하는 부분).
게임이 초기화되면 Wwise가 종단점의 오디오 구성(예: 2.0, 5.1, Windows Sonic for Headphones, PS5 3D Audio)을 알게 되며 종단점에 알맞은 형식으로 오디오를 렌더링하게 됩니다.
오디오 오브젝트의 출현
수년간 선형 혹은 비선형 오디오를 믹싱하는 사운드 엔지니어는 그 당시 제공되는 최다수의 오디오 채널(5.1, 7.1 등)로 고품질의 스피커를 사용하여 제어된 환경에서 작업을 하는 것을 최적 표준으로 삼아 왔습니다. 이 방법은 보다 적은 채널에서도 소비자 수준의 다양한 청취 환경에서 여전히 일관적인 믹스를 제공하고 대사를 명확하게 전달할 수 있게 해주었죠. 이 접근 방식은 기능적이지만 앞서 말씀드린 채널 기반 형식을 사용한 공간화 인코딩의 제약으로 인해 공간적인 정확도가 떨어집니다.
최종 사용자에게 보다 나은 공간화를 제공하기 위해서는 방향성의 인코딩을 종단점에게 위임하는 것이 좋습니다. 채널 구성은 사용자에 의해 혹은 오디오 체인에 있는 나머지 장치(예: 수신기, TV, 사운드바)에 의해 결정되기 때문에 종단점에서는 최종 사용자가 콘텐츠를 청취하는 방식을 보다 정확하게 알 수 있습니다. 그렇기 때문에 종단점은 가장 적합한 렌더링 방법을 사용하여 헤드폰이나 스피커로 최종 믹스를 전달할 수 있죠.

오브젝트 기반 형식을 사용하면 방향성 인코딩을 종단점에게 위임하게 됩니다.
방향성을 최적으로 렌더링하기 위해서는 애플리케이션이 일련의 오디오 오브젝트와 관련 메타데이터로 구성된 풍부한 정보를 반드시 종단점에게 제공해야 합니다. 좀 더 정확하게 말씀드리자면 오디오 오브젝트는 오디오 버퍼와 이에 따른 메타데이터로 구성되어 있으며, 종단점으로 전송되기 전에 Wwise 렌더링 파이프라인에 의해 생성되며 변경됩니다. 오브젝트에 연결된 메타데이터 종류는 Wwise에 의해 생성되며 오디오와 플러그인 정보에 관련되어 있습니다 (아래 그림의 파란색 상자). 이 정보는 게임 엔진으로부터 게임 오브젝트가 전달하는 정보 종류와 다릅니다 (초록색 상자).

오디오 오브젝트와 함께 제공되는 메타데이터의 종류 (파란색 상자) vs. 게임 오브젝트에 의해 제공되는 정보 (초록색 상자).
마치는 말
이 글은 각 사용자마다 다른 최종 사용자의 실제 장치에 의해 실행되는 오브젝트 기반 오디오가 공간화의 품질과 정확도에 관해 가져다주는 장점을 설명해줍니다. 이 새로운 방법은 더욱 자연스러운 소리의 공간화를 제공해줄 뿐만 아니라 저작 과정에서도 추가적인 고려 사항을 제공해줍니다. 그 부분에 대해서는 세 편으로 구성된 블로그 시리즈의 다음 글에서 살펴봅시다.

댓글