
人工知能(AI)の研究と開発が急激に前進している時代です。もうSF小説や映画の話題だけではありません。世界的にインターネットアクセスが広まり、演算用ハードウェアや機械学習、ニューラルネットワークの向上などのおかげで、今日の状況が成立しています。実に驚異的な発展が遂げられた分野です。AI時代は既に到来し、発展し続けます!
今までのAIの実績が、ゲームオーディオを含むゲーム開発全体に良い影響を与えてきました。私たちのチームがボイスオーバーを制作した最新プロジェクトで、AIの技術がいかに時間と手間の削減に役立ったのかをここで紹介したいと思います。
Mad Head GamesとWargamingの提携で開発された Pagan Online は、スラブ神話に影響を受けたファンタジー世界の設定で、目まぐるしい速さで展開するハック&スラッシュ系アクションRPGです。Co-opミッションや、狩猟や、暗殺計画のほか、50時間を超えるコンテンツのリッチなキャンペーンもあります。これを書いている時点で、ゲームはアーリーアクセスが可能で、 Steam や WargamingでPC版が入手できます。当然わが社にとって、今までにない野心的なプロジェクトでした。

PAGAN ONLINE: Kingewitchをプレイヤーキャラクターにした、キャンペーンレベルのスクリーンショット
Mad Head Gamesの沿革
私たちのスタジオの歴史に触れずして、このストーリーを語れません。Mad Head Games (MHG) は、優れた技術力をもった友人同士が数人集まって2011年、セルビアで設立されました。今年に入るまで、私たちのスタジオの代表作はHOPA (Hidden Object Puzzle Adventure) で、 Rite of Passage や Nevertales などのタイトルが有名でした。会社が成長するとスタジオの人数も増え、その多くがもとからの熱心なゲーマーでもあったので、今までと違うタイプのプロジェクトをやってみたい、という気持ちが生まれました。
そして3年以上前に、Pagan Onlineとして知られるようになる今回のプロジェクトが始まりました。ゲームやスラブ神話に対するみんなの共通した熱い想いが、このゲームの開発を推し進めてきました。その時点で、Unreal Engineやマルチプレイヤーゲームの開発を本格的に経験した人はいませんでした。オーディオチームも含め、やりながら覚えた人ばかりでした。私たちはPagan Online以前は、HOPAとモバイルゲームのサウンドエフェクトをつくったことしかなく、独自ゲームエンジンを使い、独自プログラミング言語で実行していました。
MHGのサウンドデザイナーたちはフルタイムの社員で、次の信条を共有しています。
「サウンドをつくった者が、それをゲームに実装する。」
つまり、すべてのサウンドデザイナーが、基礎的なプログラミングやソースコントロールの仕組みを理解している必要があります。だからこそ新しいエンジンを取り入れたり、Wwiseをミドルウェアとして使いはじめたりすることも、すぐにできたのです。
実践しながらの技術習得は、もちろん良し悪しがあり、必ずしも正統派の学習方法ではありません。なぜ最初にこう釈明するかというと、私たちのやり方が、学問的に、最善の方法ではなかったかもしれないからです。それでも前向きに、覚えながら、仕事をしました。私たちはAAAタイトルのプロダクションを経験していませんでしたが、自分たちのパイプラインを部分的にでも自動化する必要があると気づきました。それがAIを追求するきっかけでした。
開発の背景
HOPA系のゲームはストーリーありきなので、たくさんのダイアログが入ります。セルビアでネイティブの英語スピーカーをみつけるのは難しいので、ボイスオーバーのレコーディングは外注するというのが、スタジオとして論理的な判断でした。私たちはボイスオーバーを受け取り編集してから、ゲームに実装すればいいだけです。Pagan Onlineの開発を始めたときも、最初はこのワークフローを使い続けました。では、私たちのプロダクションパイプラインを説明します。
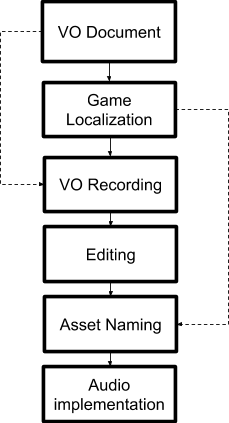
Mad Head Gamesの、当初のVOプロダクションパイプライン
上図で分かるとおり、まずナレーションデザイナーがセリフを書きます。次にプログラマーがゲームにダイアログのテキストを実装します。すべてのセリフを1つのローカリゼーションファイルに入れ、それぞれに固有の識別子ストリングをアサインします。
ch1_archives:dlg_horrible_11 "Something horrible took Riley!"
HOPAローカリゼーションファイルのダイアログラインの一例(「Rileyが恐ろしいものに連れ去られた!」)
そのあと、このVO(ボイスオーバー)ドキュメントを声優たちに送ります。声優さんが、我々の指示書だけをたよりにセリフを録音します。そして何回かのとり直しも含めた、編集されていない生の長いオーディオファイルが送られてきます。私たちはこれらのファイルを編集し、ベストなパフォーマンスだと思うものを選択し、ファイル名をつけます。ファイル名は、ローカリゼーションファイルの識別子をもとに、固有の名前(例 vo_ch1_archives_dlg_horrible_11.ogg)とします。つまり、ボイスエディターがオーディオファイルを1つ1つみて、手作業でファイル名を変えていくのです。この処理は手間も時間もかかり、面倒です。HOPAゲームだけをやっていたころには大して問題になりませんでしたが、Pagan Onlineの開発を始めたときから、課題が顕わになってきました。
このゲームはセリフの数が圧倒的に多く、WwiseとUEを使うので、まずオーディオファイルに名前を付け、インポートし、Sound Voiceコンテナを作成し、イベントを作成し、それぞれ適切なバンクに入れ、最後にUEでもすべてのイベントを作成する必要がありました。なお、このプロジェクトには人間の読めるグローバルなローカリゼーションファイルがありません。代わりにUEのDataTablesを複数使うのですが、読みやすい形式ではありません。一気にフラストレーションがたまりました。
Nuendoの Rename events from list という機能を調べました。使えそうでしたが、最初にオーディオファイルをリスト(ゲーム)で出てくる順番に整理する必要がありました。私たちはボイスオーバーのレコーディングを外注するので、声優を全員1つの部屋に集めて収録する、という贅沢はできません。また、演技の指示をリアルタイムで出すこともできません。それぞれの声優から別々にファイルが送信されてくるので、様々なキャラクターが互いに話すのを聞けるのは、全員がセリフをレコーディングし終わってからです。たとえ待ったとしても、セリフをゲーム中の順番に並べていくのは、非常に大変な作業です。私たちに必要だったのは、声優からファイルが納品される度に、そのファイルを編集して名前を付けるツールでした。
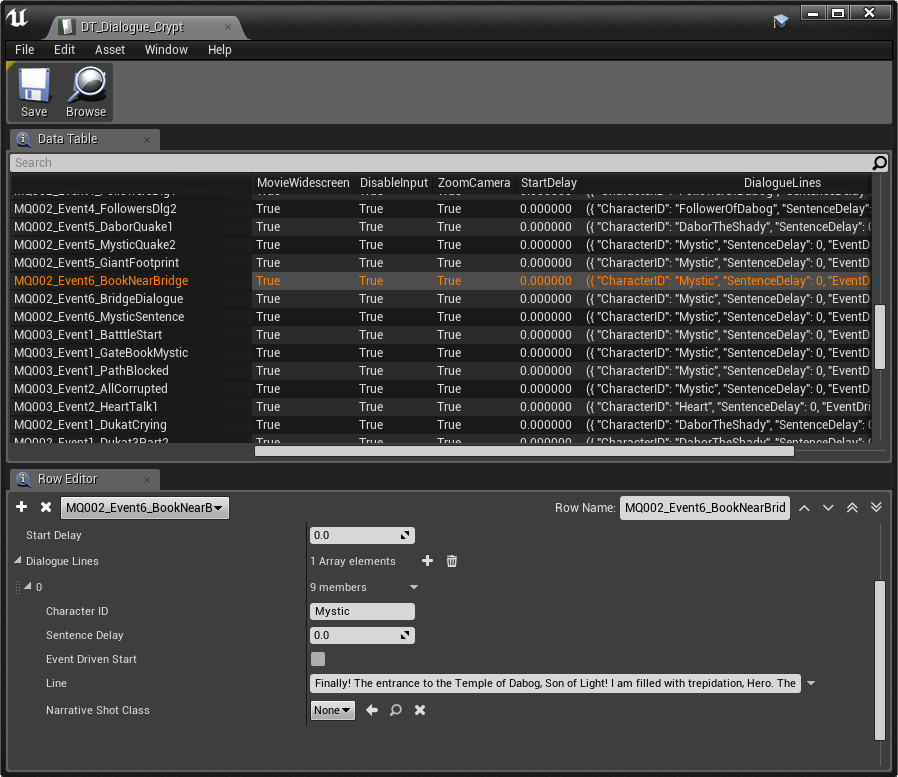
典型的なUEのダイアログ用DataTable
私は自分たちの状況をさらに細かく分析し、ボイスオーバーの制作と実装をもっと速く、効率化させるための、解決すべき点を洗い出しました。
- Datatable命名規則
- AkEvent命名規則
- イベントの自動トリガー
- オーディオファイル命名の自動化
- Wwiseにおける自動オーディオインポート
- Wwiseイベントの自動作成
これらはほとんどが、すぐに解消できました。DatatableのダイアログIDに基づいて、ストリングでAkEventを検索するブループリントをプログラマーが作成しました。意見合わせをして基本的な命名規則を決め、それを一貫して通せばいいだけです。特にWwiseのコンテナやイベントの自動作成で手こずるのではないかと思いましたが、Wwiseで TSV を利用する方法について知ると、問題は解決したようなものでした。
オーディオファイル命名の自動化ソリューション
さて、オーディオファイルを手作業で名前変更する過程では、具体的に何を行っているのでしょうか。まずオーディオを聞き、特定のファイルで聞こえてくるテキストをみつけ、自分たちで決めた規則に従い、適切な名前をつけます。つまり聞く、探す、そして命名する、という3つの処理を行います。最初の処理が最重要です。ただオーディオファイルを聞けばいいだけではありません。オーディオに組み込まれたメッセージを理解する能力が必要となります。メッセージとは単なるテキストで、それを脳で音から意味あるテキストに変換します。つまり、この処理を自動化するには、録音された音声をテキストに変換するシステムが必要です。AIの助けを活用できるポイントです。幸運にもこのシステムはすでに実在し、その名も文字通りSpeech to Textです。音声認識は新しい技術ではありませんが、スマートフォンの台頭とともに、音声認識の質が向上し、入手しやすくなりました。
一方、音声 は本来ダイナミックです。音声の聞き間違いは人間同士で話していてもよくあることです。マシンは、まだ人間ほど声の背景やイントネーションを理解できないので、誤解が生じる可能性が高くなります。いずれ技術的に解消される問題ですが、それまでの間、アルゴリズムが解釈した音声と実際に話された内容を比較する手段が必要です。マッチングの割合を把握する必要があります。まとめると、次の2つのシステムが必要でした。
-
音声をテキストに変換
-
ストリングの大まかな比較
目標を達成するのに最も重要な点は、ユーザビリティでした。技術が存在するだけでは不十分だということです。私たちの目的に合った形で技術を活用し、同時にDAWでファイルを編集できる仕組みが必要でした。
MHGではREAPERを使っていますが、柔軟性と拡張性が極めて優れているので、私たちの条件にぴったりのプラットフォームでした。REAPERはLua、Eel、Pythonのスクリプトに対応していて、速さや移植性が優れているのは最初の2つですが、モジュールの膨大なデータベースがあるのは、Pythonです。
いくつかのソリューションを検討し、テストと失敗を繰り返し、数週間後に仮のソリューションができあがりました。ReaCognitionというREAPER用のPythonスクリプトをつくり、 SpeechRecognition と fuzzywuzzy ストリングマッチングを使い、ダイアログファイルを自動的に命名できるようにしました。
ReaCognition
スクリプトでオーディオファイルの選択された部分をスキャンし、音声認識を行います。テキストが返ってくるので、それを、ゲームのセリフがすべて入っている専用のデータベースと比較します。このデータベースは、スクリプト実行前に準備しておきます。合致するものがみつかると、ダイアログラインのIDを使い、スクリプトがそのオーディオファイルに固有の名前をつけます。
(新)プロセス
下図は、ダイアログ制作の新しいパイプラインです。前とほぼ同じプロセスですが、決定的に違うのがReaCognitionの追加です。それでは各手順を詳しくみながら、何が変わったのかを説明します。
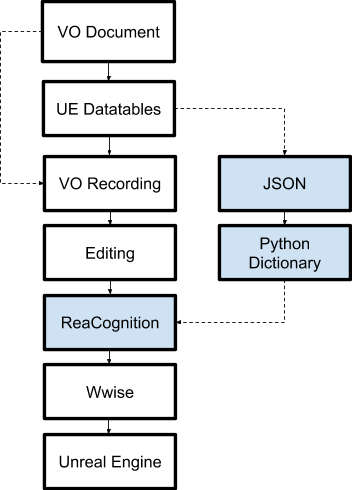
1. VO Document
ナレーションデザイナーがゲームのダイアログラインをすべて書き出し、1つのドキュメントに整理します。
2. UE DataTables
プログラマーがDataTableを使い、VO Documentのダイアログラインをゲームに実装します。
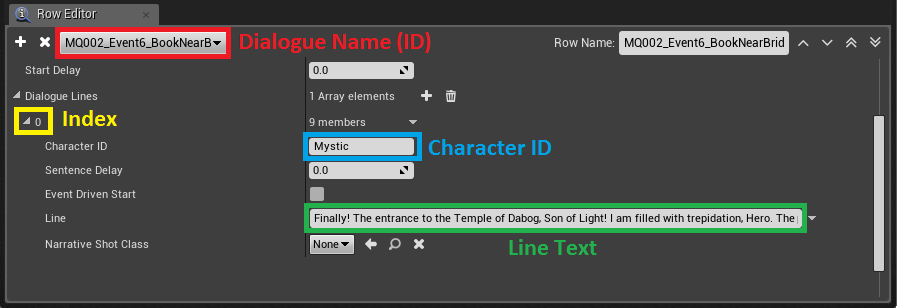
あるダイアログラインの詳細を示すDataTable
上記は、 Crypt というエリアのDataTableにあるダイアログラインの情報です。データが数行、2列にわたり表示されています。DataTableは、 辞書 のように機能します。左側にキーがあり、右側に設定値が表示されています。各ダイアログは固有の名前(ID)がつき、その中に複数のラインが入っています。各ラインに、インデックスとCharacter IDが設定されています。ランタイムに特別なブループリント(BP_DialogueManager)がデータベースから値を抽出し、このformulaを使って長い文字列 を作成します。以下がAkEventストリングをつくるためのformulaです。
FORMULA: DLG_(Area)_(DialogueID)_(Index)_(CharacterID)
例:
DataTable: Crypt
ID: MQ001DukatAppears
Index: 01
Character: Dukat
Line: Hello there! How can I help you?
AkEvent name: DLG_MQ001DukatAppears_01_Dukat
AkEvent name stringは、AkEventをトリガーするために使います。こうすれば、私たちのUEプロジェクトの中に、何百ものAkEventアセットをつくる必要がありません。Wwiseプロジェクトの中に確実にEventを入れ、対応するダイアログバンクをロードすれば充分です。
BP_DialogueManager がテキストボックスを作成し、AkEventをトリガーする
3. VO Recording、Editing
声優たちが、それぞれのセリフをレコーディングして長いオーディオファイルを返送してくれます。次にVOエディタがファイルを編集し、一番よい録音を選び、修正やクリエイティブな処置を施します。
4. ReaCognition
4.1ダイアログデータベースの作成
ReaCognitionを使う前に、ReaCognitionダイアログデータベースを作成、または更新する必要があります。これは専用のPython辞書 ファイルで、 すべてのダイアログDataTableの、最新のダイアログラインが入っています。このファイルでは、キーがAkEvent名であり、値はセリフそのです。このデータベースの作成は2段階に分かれています。まずUEですべてのダイアログDatatableを選択し、JSONファイルとしてエクスポートします。
UEのDataTableのコンテキストメニュー
次にREAPER上で特別なスクリプトを実行し、すべてのJSONファイルからデータを収集して1つの大きな辞書 に保存します。この辞書 は、AI音声認識のテキストと比較するのに使います。

ダイアログデータベース作成が完了したあとのコンソールのメッセージ出力
4.2アイテムの命名
この時点で、REAPERでオーディオアイテムの命名を始めることができます。ボイスエディタが、アイテムやアイテムの一部(タイムセレクションを使う)を選択し、ReaCognitionスクリプトを実行します。数秒後に、下図のようなメッセージボックスが表示されます。
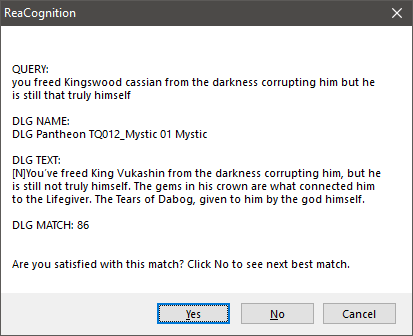
ReaCognition出力のメッセージボックスの例
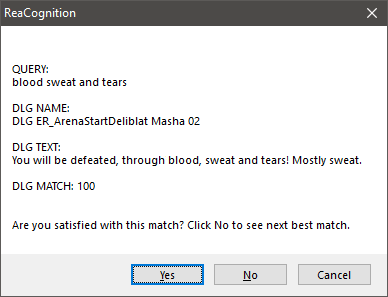
- QUERYは、選択したオーディオアイテムからAIが認識したテキスト。
- DLG NAMEは、検出されたダイアログライン名。
- DLG TEXTは、ダイアログラインのテキスト。
- DLG MATCHは、QUERYとDLG TEXTのマッチング率。
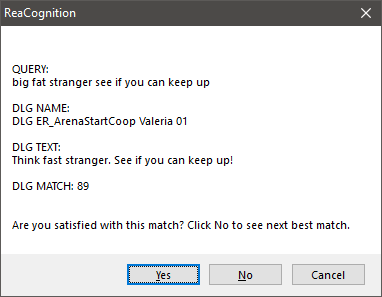
AIが特定の言葉を誤認した例
これは、明らかに一部の言葉を完全に誤認している例です。ほかの言葉を正しく認識できている限り、問題ではありません。スクリプトは必ず、クエリに最も近いマッチを探します。多くの場合、求めている結果が最初に出てきますが、違えばNoをクリックし、次にマッチ率が高い候補を表示させます。
結果に満足したらYesをクリックすれば、このオーディオアイテムに新しい名前が付けられます。
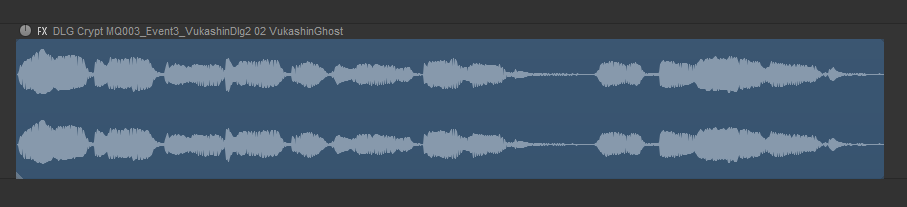
ReaCognitionを使って付けられたオーディオアイテム名
注: 名前のformula部分を見ると、データ値の間がアンダースコアでなくスペースになっています。この理由は、あとで説明します。ReaCognitionを使う上で、安全性と速度という2つの面があります。
安全性をとると、必ずボイスオーバーのラインをすべて、スキャンします。そうすれば間違いなく一番よい結果を得ることができますが、オーディオが長ければ長いほど、時間がかかります。速さをとるのであれば、VOラインの一番認識しやすくユニークな部分だけを選択します。ただしその場合は、ダイアログデータベース全体の中で選択したオーディオ部分がどれだけユニークなのかに、マッチング率が左右されてしまいます。どちらかを、かしこく選ぶことが非常に重要です。この考え方は、以下の例でよく分かります。

ReaCognitionを使い、ボイスオーバーの一部だけをスキャン
ボイスオーバーを部分的にスキャンしたあとの、ReaCognitionの出力
マニュアル版ReaCognitionAIだけではどうしてもオーディオの中身を理解できない状況がでてきます。そういった場合 のために、スペシャルモードをつくりました。ユーザーはオーディオアイテムを選択し、テキストボックスに自分で入力してクエリをつくります。句読点は必要ありません。大文字小文字の区別も不要で、単語の順番が入れ替わってかまいません。Recognize(認識)しようとしているボイスオーバーの中から、必要十分な数の、特徴ある単語を選べばいいだけです。

クエリを自分で入力
5. Wwiseで、コンテナやイベントの作成
すべてのアイテムに適切な名前を付け終わったら、次にレンダリングしてWwiseプロジェクトにインポートします。柔軟なREAPERのレンダリングエンジンを使い、レンダリングを施します。私たちの場合はファイル名にワイルドカード $item を使い、絶対的な場所に、すべての選択したアイテムをレンダリングしました。インポート作業は、もうすこし複雑な問題でした。私はこの部分の処理を、TSVファイルを使い自動化しました。Wwiseのこの点について知らない方むけに説明しますと、オーディオファイルのパスと、コンテナやイベントの、事前に決めた構成のテキストリストを使い、コンテナやイベントを作成する仕組みです。とてもパワフルで、唯一TSVよりもパワフルなのは WAAPI だと思いますが、私はReaCognitionを作った時点でそれを知りませんでした。
まず、すべてのオーディオアイテムを選択し、それらをレンダリングしてからTSVファイルを作成するスクリプトを実行し、自動的にコマンドラインを使ってWwiseにインポートします。
前述のReaCognitionの出力で、オーディオアイテム用に生成された名前にスペースが一部あることに気付いたと思います(例 ”DLG MQ001DukatAppears 01 Dukat”)。AkEventの名前はアンダースコアしか使えませんが、オーディオファイルやコンテナにはそのような制限がありません。私はこれを長所として活かし、選択中のオーディオアイテムの名前に入っている情報を使い、TSVファイルを生成させています。スペースは、情報をパースするために使われます。名前の各部分が、特定のコンテナと対応しているのです。
<WorkUnit> Dialogue
<Actor-Mixer>Dialogue
<Actor-Mixer> Map
<Actor-Mixer> DialogueID
<Sound Voice>Filename
<Sound Voice>Filename
<Sound Voice>Filename
黒字のラインは絶対パスで、青字のラインは相対パス(オーディオアイテムによって異なるパス)です。同じロジックをイベント作成にも適用しましたが、スペースをアンダースコアで入れ替えました。
AudioカテゴリのダイアログのWorkUnitを自動作成
6.Unreal Engine
最後に、新しく作成したEventでダイアログのバンクを構築します。ゲームでダイアログボックスが出現すると、Blueprintが自動的にオーディオをトリガーします。
まとめ
私たちのVOプロダクションパイプラインにどういった問題があり、どうやって解決したのかを、分かりやすく説明したいと思い、この記事を書きました。このソリューションを気に入ってくれて、同じようなことを自分のプロジェクトでもやってみたいと思った方は、是非とも連絡してください。ReaCognitionは1つの特定のプロジェクト用に作成したツールですが、今後は、このようなツールの確かなニーズがあれば特に、積極的に公開したいと計画しています。
繰り返しますが、このワークフローや、ReaCognition自体も、ベストなソリューションだとは限りませんが、私たちが使った対応策なのです。これをゲームオーディオのコミュニティに紹介することで、お互いに学びあうことを希望しています。MHGのオーディオチームは、このプロセスに対する助言や意見を歓迎します。改善のアイディアがあれば、もしかしたらReaCognitionを使う必要もなくなるかもしれません。私たちはAAAゲームのオーディオプロダクションの経験が少ないので、やり方が間違っている可能性もあります。そうであればもちろん、教えてください。
音声認識の活用は、ゲーム開発におけるAIの潜在力を示す、ほんの一例です。これからのゲーム開発業界では可能な限りのタスクが自動化され、人はクリエイティブな能力だけを使えばいいような、明るくてエキサイティングな未来があるという気に、少しでもなったでしょうか。そのような環境が実現すれば、成功への鍵は「品質」だけです。

コメント