
« 11-11 : Memories Retold » is a narrative game, set during WW1, following the story of two characters on the western front. Harry, a young Canadian who enrolled as a war photographer. And Kurt, a German father, who is going to the front at the search of his son who disappeared. The player plays both characters alternately. This is not a shooting game, it is about the story of the two characters and people affected by war, on both sides. The game alternates between exploration and narration sequences, in a third person perspective.

The game has been developed by Digixart in Montpellier (France), Aardman Animations (Bristol) and published by Bandai Namco for PC / PS4 / XboxOne (released on November 9th, 2018). The visual of the game is very unique, with its painterly effect rendering the game in real-time, as a living painting, composed of thousands of strokes drawing the game.

Elijah Wood lent his voice to Harry, and Sebastian Koch to Kurt. The music was composed by Olivier Deriviere. Olivier Ranquet delivered precious assets and Antoine Chabroux was our sound intern. I was primarily in charge of the technical side of the audio (Wwise project management and integration in Unity, custom audio tools, and some SFX and foley design).
Wwise was an obvious choice to manage the audio for the game for the following reasons:
- multi-platform game : Conversion and Stream management per platform was easily manageable, as well as profiling / optimizing / debugging
- it has built-in functions to manage the logic involved in switching between two characters in two different location (which is a big feature of the game)
- we were a small dev team and I was working remotely : being independent in my work was important and Wwise also reduced the workload for programmers
Early work
This was the first game of this scale for DigixArt and Aardman, with a freshly formed team. There was no audio pipeline in place for Wwise and the visual scripting tool used in Unity didn't had built-in nodes for Wwise. I was brought early in the production, which gave us the time to have a proper pre-production period. The goal was to have a solid audio pipeline before getting into the busy production period ahead.
« 11-11 : Memories Retold » is a story-driven experience. Having a clear and well-crafted narration is essential. Therefore, one of my first mission was to develop a text-to-speech system between Wwise and Unity, so that level designers can pace and design the game around the voices (voice-over or diegetic dialogues).
I came upon this WAAPI sample by Bernard Rodrigue, that generates a robot voice audio file corresponding to the Notes of a Sound Voice object. After experimenting with it locally, I explained and pointed useful functions to a programmer in order for him to create a large scale system working as explained below:
- the writers were working on a spreadsheet and were updating this document daily
- a custom « audio spreadsheet » was created, importing the dialogue number and the dialogue line (cf. image below)
- this tab delimited document was then imported into Wwise, creating a Sound Voice object named after the dialogue number and having the dialogue line as Notes. An additional column was added to create a Play_ event in the correct Work Unit.
- WAAPI then generated the robot voice by reading the Notes of the newly created Sound Voice, and generating corresponding Soundbanks
This was all automated in a batch file, executed automatically every mornings. This system allowed the level designers and myself to work with always up-to-date dialogue lines. This was absolutely crucial to pace the game before the voice recording sessions (of course, some adjustments had to be made once putting the real voice in game but this system was undoubtedly a big time saver).

« Sample of the automatically created audio spreadsheet imported in Wwise »
After playing prototypes and studying the game design documentation, I came up with a list of data that I would need to get from the game engine to Wwise.
Here is a list that already covered a lot of my needs:
- Character's Switch : for everything specific to each character
- Character's States : for everything global (ambiances / music / ...)
- Character's Stance Switch (is the character crouching / running / climbing / …) : useful for all the locomotion foley
- Footsteps Material Switch and material detection system
- Character's Speed RTPC
- AkListener's position RTPCs (X, Y and Z)
- A dozen of States corresponding to different features of the game: NPC Dialogue On/Off, Cinematic On/Off, Voiceover On/Off, Puzzle view On/Off, Menu On/Off, GameView (PuzzleView / ExplorationView / CameraView / CardGameView / ...)
- and multiple core Events : Level_Start_ and Level_End_ events ; Menu and Pause events ; ...
A programmer helped me plugged these datas and developed a generic C# script attached to every character (main or NPCs). All gameplay-elements (puzzles, Harry's camera, …) also had a generic script attached, feeding Wwise with the current state of the puzzle / game.
Every time a level designer added an NPC or a puzzle, all the logic system built in Wwise were applied to those new elements automatically. If I needed to modify or add something, modifying the parent prefab would update all the children in levels.
The point is, being involved early gave me the time to build generic but adaptive systems that saved me a lot of time for the integration during the production, facilitated the debug process and helped building the interactive mix along the way.
Integration and interactive systems
For all diegetic voices, I had two Attenuation Sharesets. One was realistic and simulated real-life attenuation. The other one had a very long slope and the voice was never completely attenuated/filtered and was always intelligible. Drag and dropping the Sound Voice in the Acter-Mixer with one or the other attenuation Shareset was an easy way to keep the most important dialogue audible, no matter what the player is doing.
Voice-overs can happen anytime during exploration, cinematics, exploration, puzzles, … All sort of other audio events can also occurs during those VO sequences, potentially creating intelligibility issues. We had a custom node to call voice lines. It allowed us to set if this line was narrative (VO) or diegetic, to play multiple Wwise events successively, and have different output in between events or after all events are finished.
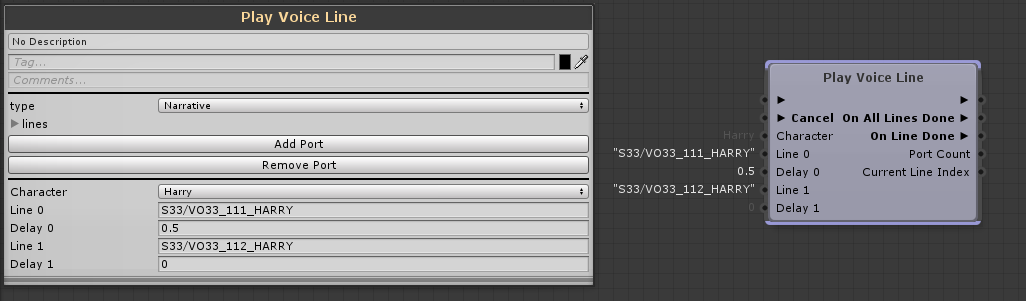
«Custom Node to play dialogues or VO »
When Set to « Narrative », it triggers different settings in Wwise affecting the mix :
- sets the VoiceOver State to On at the beginning of the first VO event and switch it back Off when the last event of the node is finished. This State ducks everything except VO (at the Bus level), coupled to high/low pass. Having this custom node allowed level designers to work granularly with VO events (adding, removing or switching VO lines) and yet keeping a generic and consistent narrative mix, no matter how many or which VO are played. I preferred the use of States over Auto-ducking as I also needed to apply this mix settings when no audio was playing in the VO bus (if applying a long delay between two VO lines for example)
- sets the RTPC_Voice_Over_Effect to 1 : this RTPC goes from 0 (when no VO are playing) to 1 (whenever a VO is playing). This RTPC lower the threshold of compressors on the music, ambience and SFX bus, avoiding louder sounds to overlap with the VO
The VoiceOver State lowers the Music bus from 3 dB. Which is clearly not enough when a full orchestra is playing loud. In order to keep a good VO intelligibility without lowering the music volume too much (and potentially hearing it pumping in and out), an EQ was filtering out of the music the most prominent frequencies of the VO. I assigned an RTPC to the meter of the VO bus ; this RTPC was driving the gain of two frequency bands. This really helped getting the VO through the loud orchestra without ducking it too much.
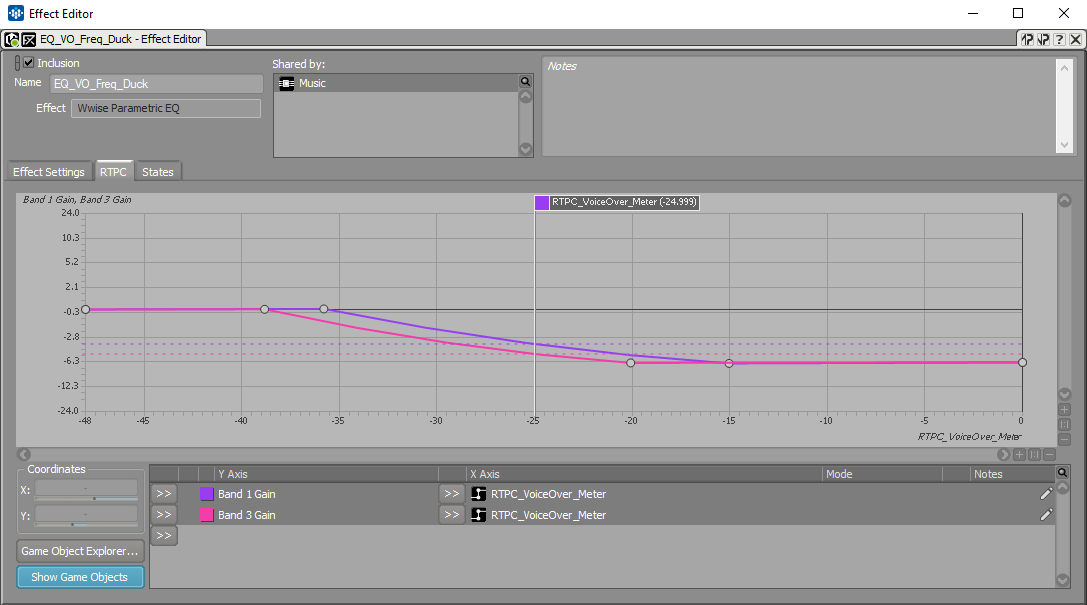
« EQ on the Music bus, with the VO meter ducking two frequencies (with a large Q) »
At some point in the game, the player will control a cat. Putting Wwise events on the animation timeline did not work well for the footsteps, as the animation speed changed depending on player's input and the « rhythm » of footsteps wasn't consistent.
To get a more convincing results, I used a random container in Continuous/Loop mode, with the Trigger Rate value driven by the cat's speed (as was the volume and pitch). Playback events were managed in code. The Play_ event occurred when the cat speed was superior to 0 and the Stop_ event was called once the cat's speed reaches 0.
Music
Composer Olivier Deriviere was involved from the very beginning of the project. He composed beautiful music that is a major actor of the game and conveys a lot of emotions. It guides and follow the narration, emphasizing Kurt's and Harry's feelings. It has been performed by The Philharmonia Orchestra and recorded at Abbey Road Studios.
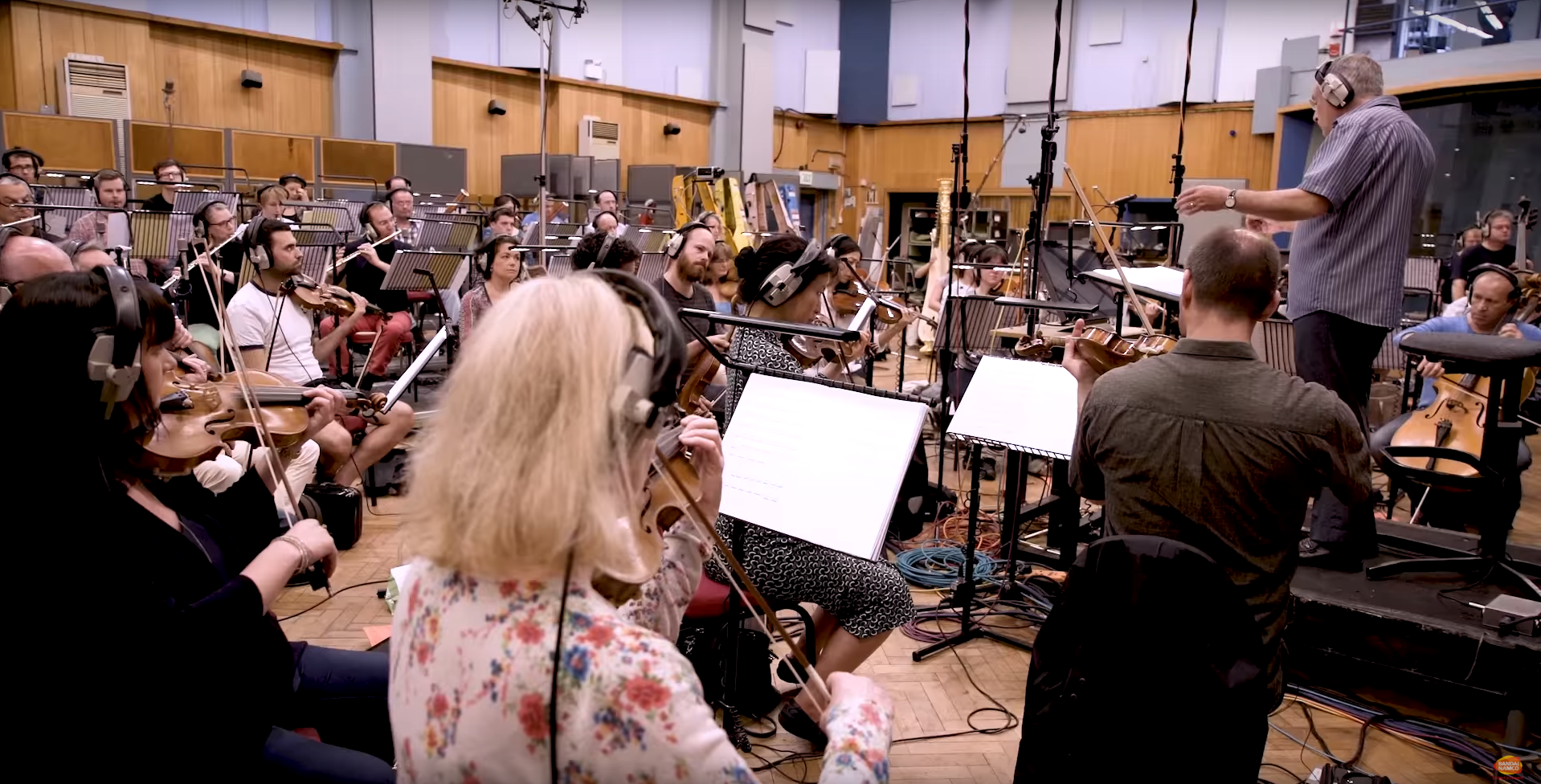
« Recording session at Abbey Road Studios »
Because of its structure, the game didn't need complex interactive music systems. The implementation work consisted mostly of carefully timing the music with the narration and objective completion. This was achieved as simply as can be : one main Switch container (played at game start) and Set States actions in various events (Level_Start, VO events) or in the visual scripting tool.
«Olivier talks about the creative and recording process»
The full soundtrack is available here .
Mix
From the many options Wwise offers regarding interactive mix, HDR was not considered because of the genre of the game. (It is quite scripted and the number of concurrent events is controlled.) I used a mix of custom side-chains, States and Auto-Ducking. The choice of State ducking over Auto-Ducking was made depending on the need of keeping the ducking even if no audio was going through the ducking bus. Each ducking applies a volume between -2 and -6 dB, which is not a lot on its own, but the mix results from the cumulation of those values depending on situations.
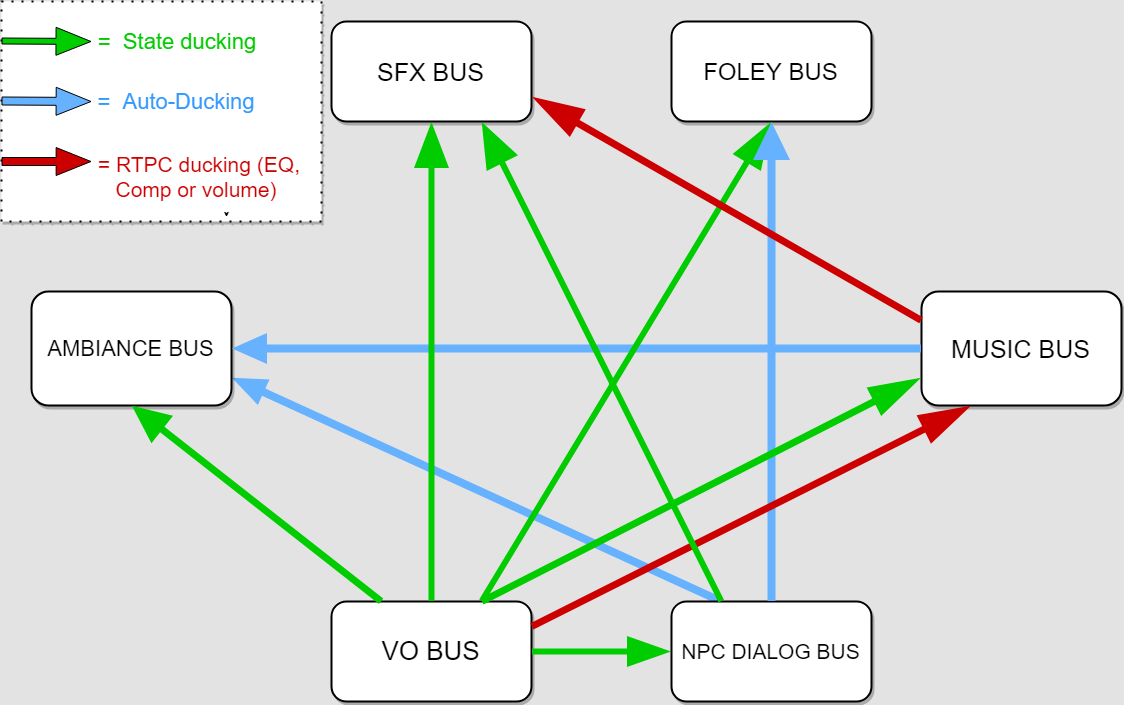
«Simplified scheme of the mix system »
Using States instead of Auto-Ducking also allowed me to enhance or soften the ducking on specific Sound. For example, if I want a specific Sound SFX to be less ducked, I add the VoiceOVer State to it and compensate the volume loss and filters that is applied on the bus level. Same goes to enhance the ducking on specific sounds.
I also used the built-in Azimuth parameter to drive an RTPC, ducking specific emitters going behind the AkListener's field of view. This helped clearing the mix and keep the player's focus. (The Azimuth parameter is also quite handy when linked to a Pitch curve, to simulate Doppler effect on planes flying over for example.)
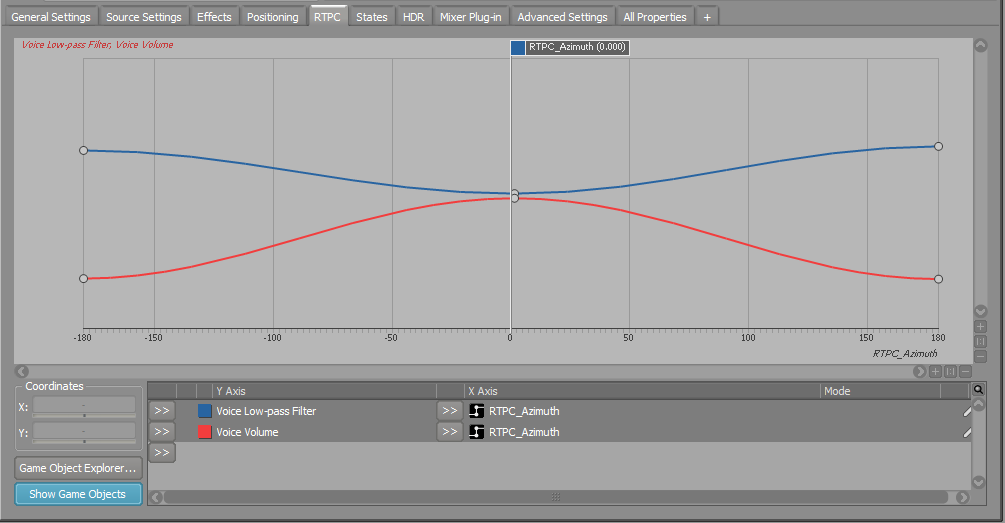
« Azimuth RTPC filter and volume curves »
Conclusion
« 11-11 : Memories Retold » is a narrative, story-driven game where music and VO have the first role in the audio landscape. With this in mind, Wwise allowed me to build generic and adaptive system to facilitate the integration, convey the story and bring emotions to the player through audio.


Commentaires